論理行番号 | ウィンドウ端で折り返し表示 | 不可視文字を表示する | 改行文字コード | 文字符号化 | 文字符号変換
エディタの超基本
Windowsで広く使われているOpen sourceとして開発されているサクラエディタおよびMacOSでよく使われているmiを例に、エディタを使う前の(あるいは新しくエディタを使い始めるに確認すべき)事柄をごく簡単に紹介する。

以下の説明では、バックスラッシュ(backslash)文字(ASCII文字コード 0x5C [16進数] 5/12 [10進数])を " \ " で表す。 バックスラッシュは、JIS X 0201文字符号化では(半角)円記号¥に割り当てられているため日本語キーボードではそのようにキートップに刻印されている(ハングルでも同様でウォン₩記号が割り当てられているようだ)。 バックスラッシュはエディタ設定あるいはOSの言語設定などによりASCII記号としての"\"として表示できる。
右図はUSキーボードの一部である。 Returnキーの上にバックスラッシュ・キー " \ " があるのがわかる。 また、セミコロン " ; " とコロン " : " の位置関係も日本語キーボードと異なることを確かめよう。 それぞれの言語地域でキーボード配列は違うことに注意しよう。 US keyboad全体写真
演習:
それぞれの言語のキー配列を調べて、日本語やUSキーボードとどう違うかを確認しなさい。 たとえば、韓国(ハングル)、中国語(簡体字)、フランス語、ドイツ語、ギリシャ語、ロシア語、アラビア語、ヘブライ語、アルメニア語など。
どうして、そのような文字をコンピュータは表示できるのかを考えでみよう。
論理行番号
ページの先頭へ論理行または段落行とは、改行文字の「次の文字」から次の改行文字までの文字列である。 論理行の先頭を行頭(beginning of line)、改行文字の「直前」を行末といい、それぞれ「行頭文字」または「行末文字」という。 改行文字と次の改行文字にある文字列は空でもよく、その場合の論理行は「改行文字」だけからなっており空行(emply line)という。 こうして、各論理行に順に1から番号をつけることができる。 これを論理行番号という。
エディタで作成されるファイルは、キーボードから入力された文字がファイルの先頭からファイルの最後(EOF: End OD File)まで連なった長〜い一本の文字列である。 つまり、テキストファイル(text file)の構造は
[ファイルの先頭] 文字列 <改行文字> 文字列 <改行文字> ........<改行文字> 文字列< 改行文字> ............. [EOF]
エディタでそのテキストファイルを表示すると、Returnキーの入力によって改行文字が入力されると、論理行が改たまって(new line)、視覚的に新たな論理行が始まるように表示される。 次のキー入力が新しい論理行の行頭文字となり続くキー入力文字が次々と追加されていく。 次の図は、MacOSのエディタ mi での様子である。 左端は論理行番号である。

上図では、27行目と34行目は空行である。 また、33行目の論理行は長く、行頭文字 [こ] ではじまり行末文字は「扱われる。」の (。) である。 つまり、33行の論理行を成す文字列は次のようになっている:
[こ]のように日本語を使う場合には全角と半角の区別は非常に大切だ。もちろん、全角空白 と半角空白 だけでなく、一般に全角英数字文字ABC123と半角英数字文字ABC123とはコンピュータ内では全く違う文字として扱われる(。)
論理行ごとに行数を数えて、行番号をつける設定をしておこう。
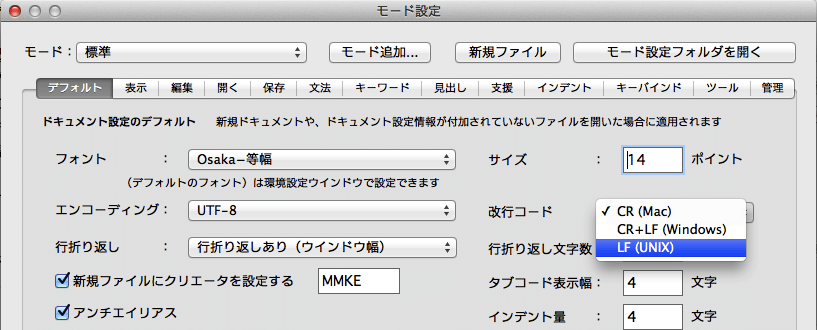
MacOSのエディタmiでは、、下図のように、デスクトップメニュー [mi]/[モード設定..]からそれぞれのモード(標準、HTMLなど自由に追加できる)において[表示]を選択し、「行番号ボタン」で段落番号を、「各行の行番号」で段落番号を選択するする。
Windowsのエディタサクラエディタでが、デフォルト設定で、論理行と論理行番号が表示される(下図参照)。
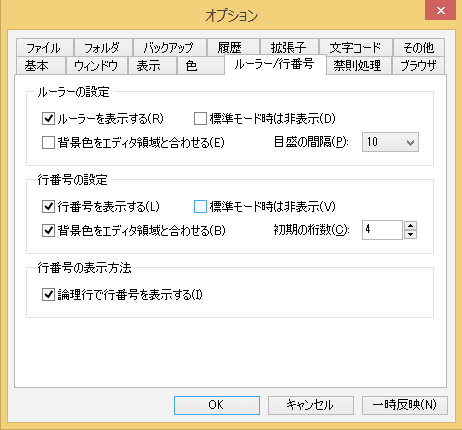 Windowsのエディタ TeraPadでは[表示]/[オプション]から[ルーラ/行番号]タブを選んで、□「行番号を表示する」にチェックを入れた上でさらに「□論理行で行番号を表示する」をチェックする。
Windowsのエディタ TeraPadでは[表示]/[オプション]から[ルーラ/行番号]タブを選んで、□「行番号を表示する」にチェックを入れた上でさらに「□論理行で行番号を表示する」をチェックする。
ウィンドウ端で折り返し表示
ページの先頭へ上図の33行目では、エディタ画面のウィンドウ幅に論理行が収まらない場合には、エディタ設定で「ウィンドウ幅で行の折り返し」がなされている。 ウィンドウ幅で論理行を右端で折り返す設定をしておこう。
MacOSのエディタmiでは、下図のように、デスクトップメニュー [mi]/[モード設定..]からそれぞれのモード(標準、HTMLなど自由に追加できる)において[デフォルト]を選択し、[行折り返し]を「行折り返しあり(ウィンドウ幅)」を選択する。
Windowsのエディタサクラエディタではデフォルト設定で行折り返しになっている。 下図のように、[設定]/[折り返し方法]から「右端で折り返す」を選択してもよい。
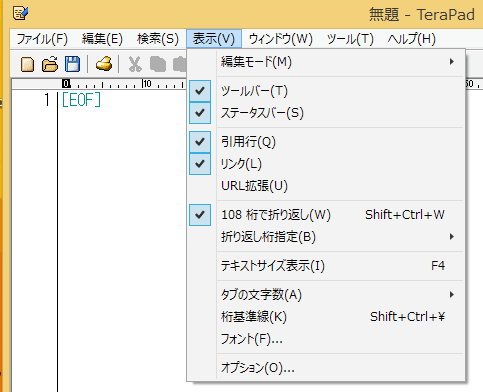
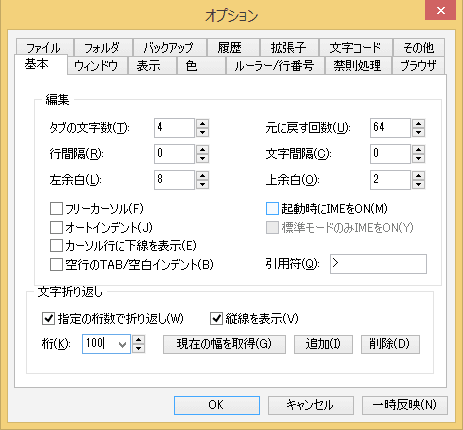 Windowsのエディタ TeraPadでは[表示]で折り返し設定するか、または[表示]/[オプション]から[基本]で文字折り返しを設定する。
Windowsのエディタ TeraPadでは[表示]で折り返し設定するか、または[表示]/[オプション]から[基本]で文字折り返しを設定する。
不可視文字を表示する
ページの先頭へ上図では、不可視といわれる目に見えない文字の集まりの中で、「空白」(blank)として視認できる文字が使われている。 「スペース文字」(space)と「タブ」(tab)である。 とくに、日本語ではスペース文字には2種類あり、半角スペースと全角スペース文字があることがきわめて重要で、それらはキー入力の際に厳格に区別される必要がある。 テキストエディアタは次のような不可視文字(imvisible letter)が表示できるものを使うべきだ。
- 改行文字(\n)
- 半角スペース文字(" ")
- 全角スペース文字(" ")
- タブ文字(\t)
ここで、改行文字 "\n" は「Backslash + n」、タブ文字 "\t" は「Backslash + t」であり、プログラミング言語において標準出力(モニタ)への文字列表示の際に使われる表記だ(たとえば print "Hello, World\n" と書くと、「Hello, World」を表示してから改行されるというように)。
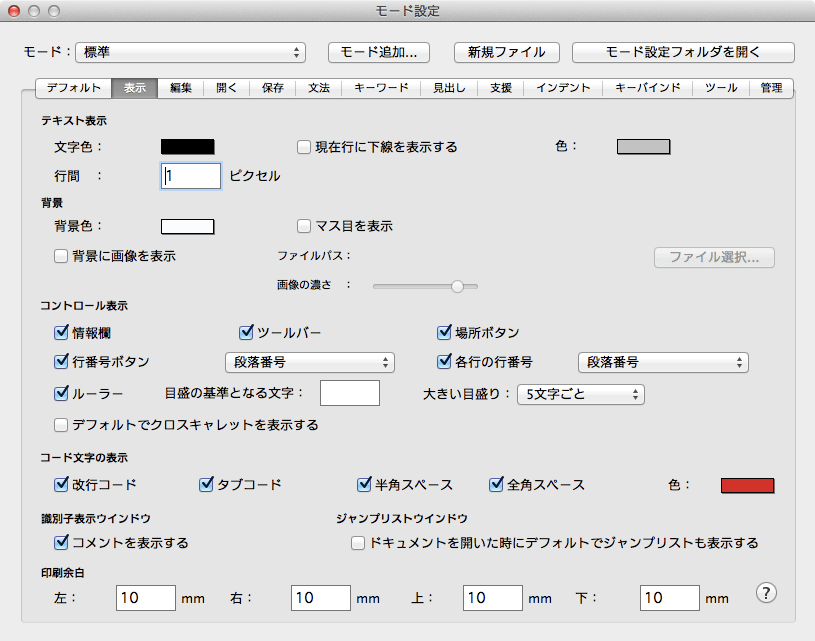
これらの不可視文字を区別してそれと分かるように表示設定するには、たとえばMacOSのエディタ mi では、デスクトップメニュー [mi]/[モード設定..]から、それぞれのモード(標準、HTMLなど自由に追加できる)において[表示]を選択し、「コード文字の表示」の各文字をチェックする(右図)。
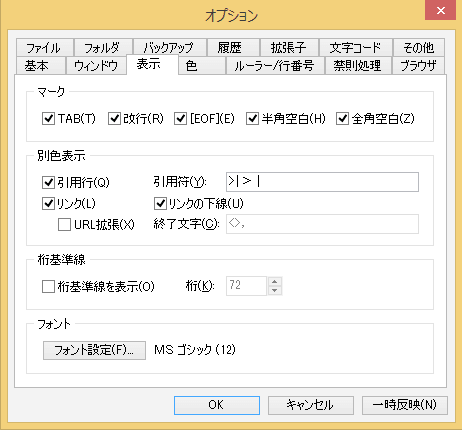 Windowsのエディタ TeraPadでは、[オプション]/[表示]から、「マーク」で TAB、改行、EOF、半角、全角空白の全てにチェックする。
Windowsのエディタ TeraPadでは、[オプション]/[表示]から、「マーク」で TAB、改行、EOF、半角、全角空白の全てにチェックする。
改行文字コード
ページの先頭へ「改行文字」という不可視文字をどのように符号化(コード化)して実現・表現するかという改行コードは、特にプログラム言語(Perl、Python、Rubyなどのスクリプト言語)では大きな問題になることがある(LFにするのが一般的だ)。 テキストエディタは、改行コードを自動判定し正常に改行表示できるものを使う必要がある(たとえば、Windowsに標準装備され [プログラム]/[アクセサリ] にある「メモ帳」はWindows標準の改行コードしか認識できず、しかも折り返し機能がないために、ファイル内容が1行としてWindows幅からはみ出してしまう)。

OSによって標準で使われる改行コードは違う。
以下、CRは「キャリッジ・リターン」(\r)で復帰、LFは「ライン・フィード」(\n)で改行という不可視コードである(括弧内はその正規表現)。
これらは、既に使われなくなって久しいタイプライターで使われていた用語である。
| OS | 改行コード | 正規表現 |
|---|---|---|
| Windows | CR+LF | \r\n |
| MacOS | CR | \r |
| Unix | LF | \n |
改行コードは、HTMLファイルやLaTeXファイル(これらはどの改行コードを使っても整形表示やタイプセットには影響を与えない)などのテキストファイルと同じ改行コードを採用するようにしよう。
MacOS用のエディタ mi では、右図のように、デスクトップメニュー [mi]/[モード設定..]から、それぞれのモード(標準、HTMLなど自由に追加できる)において[デフォルト]を選択し「改行コード」から、または下図のように、エディタメニュウのアイコンから、CR(Mac) / CR+LF(Windows) / LF(UNIX)のどれかを選ぶ。
![]()
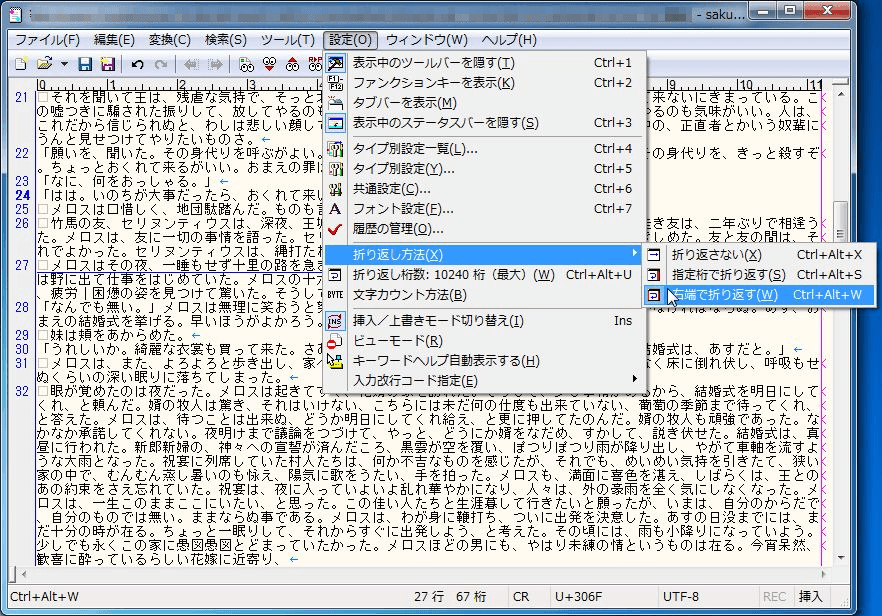
Windows用のエディタ サクラエディタ では[設定]/[入力改行コード]で、Windows CRLF / Mac CR / Unix LFのどれかを選ぶ。
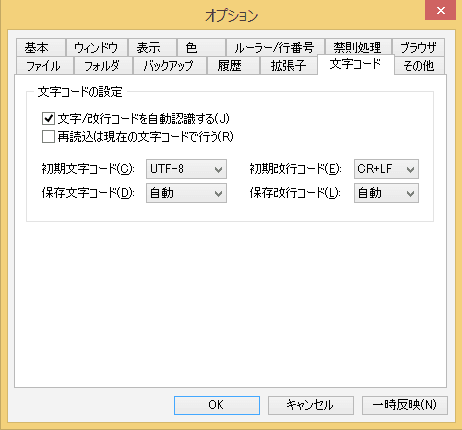 Windowsのエディタ TeraPadでは、[オプション]/[文字コード]から初期改行コードを選択できる。
図では、文字符号化をUTF-8、改行コードをWindows標準のCR+LFとしている。
Windowsのエディタ TeraPadでは、[オプション]/[文字コード]から初期改行コードを選択できる。
図では、文字符号化をUTF-8、改行コードをWindows標準のCR+LFとしている。
文字符号化
ページの先頭へコンピュータで文字を正しく表示するためには、まず利用可能な文字集合(character set)を定め、さらに各文字を数字列に対応させる文字符号化(文字コード化 character coding)を定めておく必要がある。 今日では文字コードとしてUTF-8を使おう。
もっとも代表的な文字符号化に、大小のローマ文字や数字、英文でよく使われる約物など(不可視制御文字を含む)128文字の集合をさだめ、これに7bitの整数を割り当てた文字コードであるASCII(American standard code for information interchange)がある。 ASCIIでは、たとえば "A" は 16進数で 0x41(10進数で 65)に割り当てられている。 日本文字集合としてJIS X 0208、その文字符号化にはISO-2022-JP、EUC-JPやShift_JISの複数の2バイト(16ビット)文字符号化があり、問題を複雑にしている。
しかし、JIS X 0208では、6,879文字を含むのであるが、一部の言語を除いて同時に複数の言語文字を表示することができない(しかもα, β,γなどのギリシャ語やД,Ш,Яなどのロシア文字は全角である)。 つまり、文字集合が小さいのである。 欧米の文字集合の多くは8ビット符号化で十分であるが、日本語を含めてアジア言語では漢字などが示すように膨大な文字が利用されてる。 こうした問題に部分的にせよ対応するために、大きな文字集合を定義し、その文字を1〜6バイトでの文字符号化を定めたのがUTF-8(UCS Transformation Format 8)文字符号化である。 最近のOSでは、国際化対応のためもあり内部の文字処理をUTF-8で行うようになっている(WindowsでもMacOSでも)。 たとえば、Microsoft Officeのファイルは「内部では」UTF-8文字符号化で作成されている。 Webページなどと親和性の高い電子ブックの書式EPUBがUTF-8を指定しているなど、急速にUTF-8の文字符号化が広がっている。
テキストエディタは複数の文字符号化(文字コード)を自動判定して、文字化けを起こさずに表示してくれるものを使おう(Windowsに付属の「メモ帳」も多少は改善されてきたが、エディタとして利用するには全く不十分で利用は薦めない)。 そのようなエディタでは、テキストファイルの文字コードを他の文字コードに変換して保存することができる。
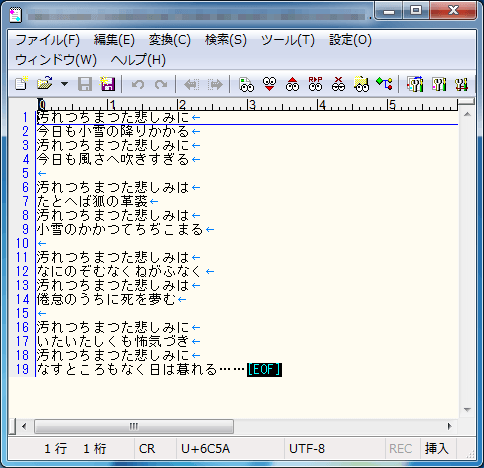
左図は、サクラエディタで開いたテキストが UTF-8 文字コードを使っていることを示している(ウィンドウ下段に「UTF-8」の表示がある)。
文字符号変換
ページの先頭へテキストファイルの文字符号化方式を別の文字符号化に変換して保存することは、あらゆる意味できわめて大切な作業だ。
MacOSのエディタ mi では、上図のように、文字コード指定のメニューアイコンから目的の文字符号化を選択(下図右)してから、保存する。
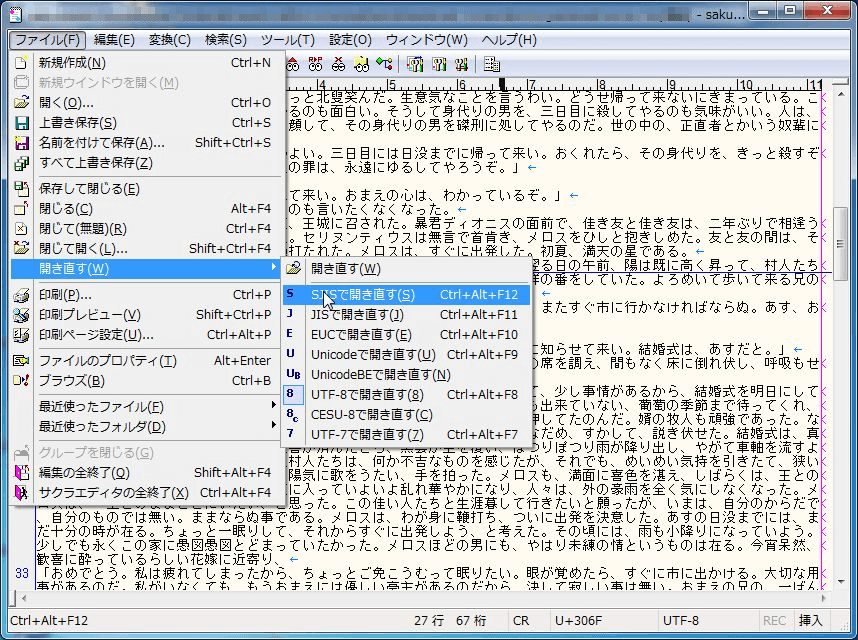
Windowsのエディタ サクラエディタ では、下図左のように、[ファイル]/[開き直す]から目的の文字符号化を選択してから保存する。

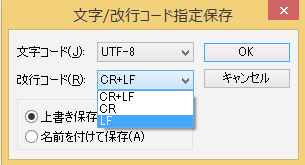 Windowsのエディタ TeraPadでは[ファイル]/[文字/改行コード指定保存]から、文字コードおよび改行コードを変換できる。
Windowsのエディタ TeraPadでは[ファイル]/[文字/改行コード指定保存]から、文字コードおよび改行コードを変換できる。
{kind=link}