第15回 統計データの整理と可視化(Numpy, Pandas, Matplotlib)
今回は、いくつかのモジュールを利用して、統計データを整理したり、グラフとして可視化する方法を紹介する。この作業を「統計解析」という。そのためにはNumpy, Pandas, Matplotlibという、密接に関連する3つのモジュールを利用する。どのモジュールも全体の仕様は相当大きいので詳細まではとても扱えないが、授業フォルダに用意したColabノートブック(statistics.ipynb)を実行すれば、データの解析について一通りの理解が得られるしくみだ。題して「統計解析入門ツアー」。そして、Colabはこれらのモジュールと高い親和性があり、さまざまな支援をしてくれる。
この回の内容
統計解析とは
大学での勉強や研究を考えてみよう。理工学部や農学部では、実験によって科学的な事実を確かめるが、そこでは実験が行われて実験データが得られる。また社会学部や政治経済学部では、アンケートによる世論調査といった手法が使われ、その結果調査データが得られる。
実験データや調査データはいずれも、統計的な手法を駆使して処理され、研究対象に関する妥当な記述・推定・仮説へと結びつけなくてはならない。だが、それらは統計的に正しく扱わなければ、正しい結論に結びつかない。実際、学生のレポートや、テレビの報道番組においてさえ、アンケート結果から統計的に無理な結論が導かれていることがたびたびある。
皆さんも、統計学の理論はともあれ、統計解析のスキルは身につけよう。それに統計的な物の見方ができると、世間で横行しているいい加減な言論を見抜く感性も身につく。
Pythonと、今回紹介するモジュール群は、統計解析入門のための最善のツールだ。
なぜEXCELではダメなのか
ダメではない! それどころか統計学の難しい理論から、統計解析の実践をきっぱり分断したのは、表計算ソフトの大きな功績だ。Excelには基本的な統計関数が用意されていて、ワークシート上に各種解析手法(たとえば母平均の区間推定)の手順を作り込める。つまりExcel文書は、一定の作業を自動的にしてくれる表という、プログラムの一種である。Excelは、統計解析に利用できる以下の要素を備えている。
- 対象データを保持するワークシート。たとえば今回の「統計解析入門ツアー」で利用する「100人の男子学生の身長と体重(shin_tai.csv)」は、Excelのインポート機能で読み込むと、図15-1のようなワークシートになる。ただし、これはあくまで書式を整えた表に過ぎず、Pandasが提供する構造化されたデータフレームとは似て非なるものだ
リスト15-1: Excelにインポートした統計データ(shin_tai.csv) - 統計解析のための基本的な統計関数群。これらを使った数式をワークシートのセルに埋め込むことで、各種統計解析手順をプログラムできる
- 未整理の生データ(レコード群)から、さまざまな統計や分析処理をオンデマンドで行える統計・データベース機能
- 対象データと処理手順(アルゴリズム)が同じワークシート上に同居しており、分離できない。アルゴリズムを再利用するには、ワークシートのデータ部分を書き換えなければならない
- 処理手順を記述したプログラムが、セル上の数式の集合体に過ぎず、全体を見通せず、さらに複雑な解析をするためにプログラムを構造化できない
大げさにいえば、今回の授業の目的は、履修者を、現実の複雑なデータを読み解き、見えない情報を引き出すデータサイエンティストの道に誘うことである。
Python界の「統計三銃士」:Numpy, Pandas, Matplotlib
Excelに代わって紹介するのは、Numpy, Pandas, Matplotlibという3つのモジュールである。「新しいモジュールを3つも習うの!」と言われそうだが、これらは密接に協力しながら仕事をこなす「三銃士」であり、Numpyを除けば、他の2つが単独で使われるのを見たことがない。役割分担は以下。
- Numpy
- 行列演算モジュール。統計解析では行列演算が多用されるが、Pythonには1次元のリストしかなく、2次元の配列さえない※2
- Pandas
- 対象のデータを構造的に保持できるデータフレームを利用するためのモジュール。Excelワークシートの上位互換にあたるデータ構造であり、統計解析の対象データを、処理手順のアルゴリズムとは独立に保持できる
- Matplotlib
- 多機能で使いやすいグラフ表示モジュール。Excelのグラフ作成と同等かそれ以上の機能を提供する
2 そのように映っていたのは、リストのリストだ。行列計算のプログラムは書けるけれど、実行速度は致命的に遅く、とても実用にならない(計算の直前まで文字で書かれていたデータだから当然だろう)。そのため、主として科学技術計算の分野でPythonを使う時には、常習的にNumpyが使われる
統計解析入門ツアー
今回は時間的制約が大きいので、説明はこのくらいにして、さっそく具体的な統計解析をやってみよう。対象データは図15-1で紹介した「100人の男子学生の身長と体重(shin_tai.csv)」である。Colabノートブック(statistics.ipynb)と一緒に授業フォルダに置いてあるので、いつもの作業ディレクトリにアップロードしよう。
まず、100人の身長データを使って1次元(1変量)の解析と視覚化(グラフ化)を行う。
つぎに、身長-体重データを使って2次元(2変量)の解析と視覚化を行う。最初のコードセルから順に実行してほしい。モジュール内の各関数について詳細な解説はできないが、出力アクションを追っていけば一応の理解はできるはずだ。テキストセルにも簡単な解説を書いた。
このリストは大変長いので、①~⑤に分けて掲載する。
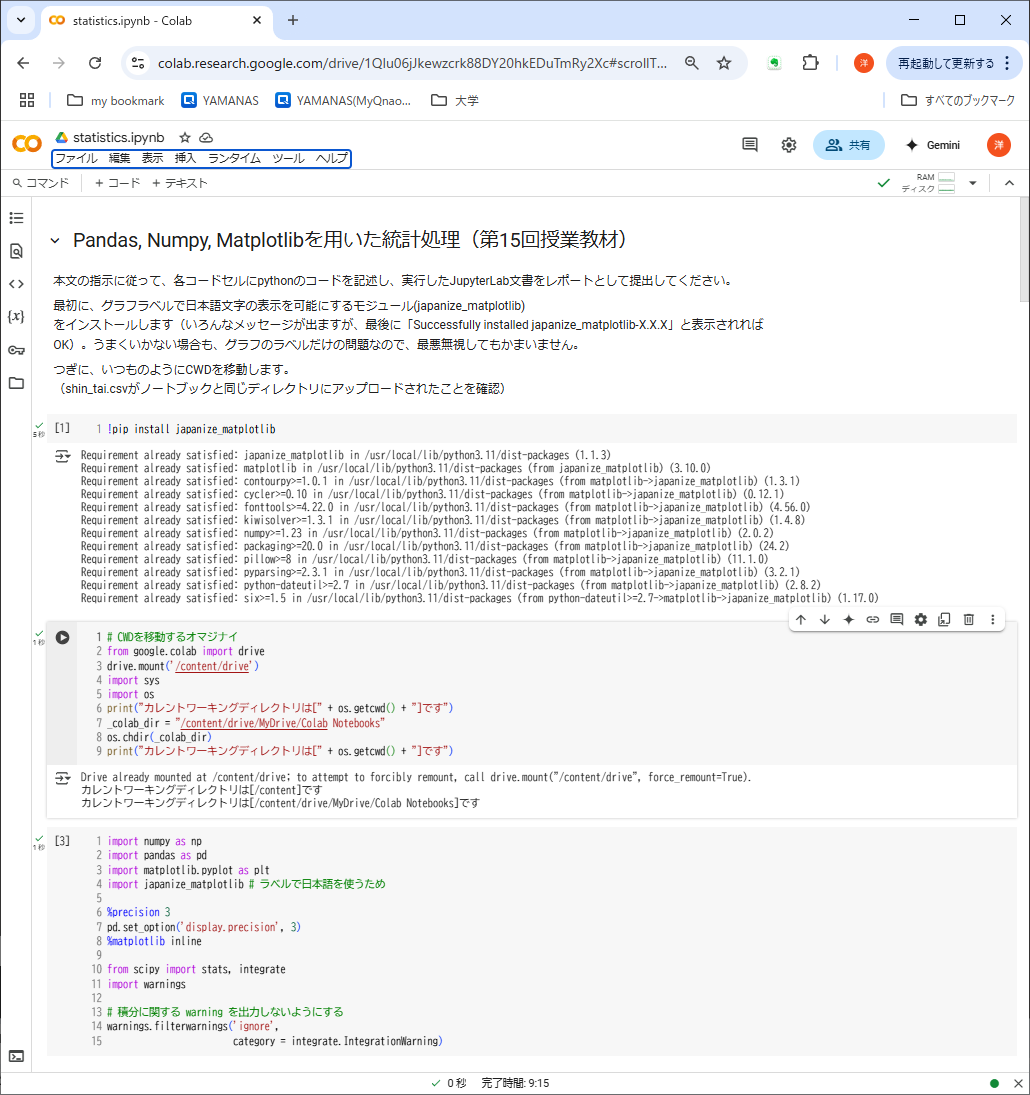
①の処理内容(準備段階)
- グラフラベルで日本語表示を可能にするモジュール(japanize_matplotlib)をインストール(2度目なので「インストール済です」という内容のメッセージが出ているが、初回なら「Successfully installed japanize_matplotlib-X.X.X」と表示されるはず。インストールに失敗しても、ラベルだけの問題なので、最悪無視してよい)
- Googleドライブをマウントし、CWDを移動するいつものオマジナイ(第6回講義資料からコピペ可)
- 必要なモジュールをimportし、浮動小数点数の表示桁数や積分に関するwarning抑止などの細かい準備
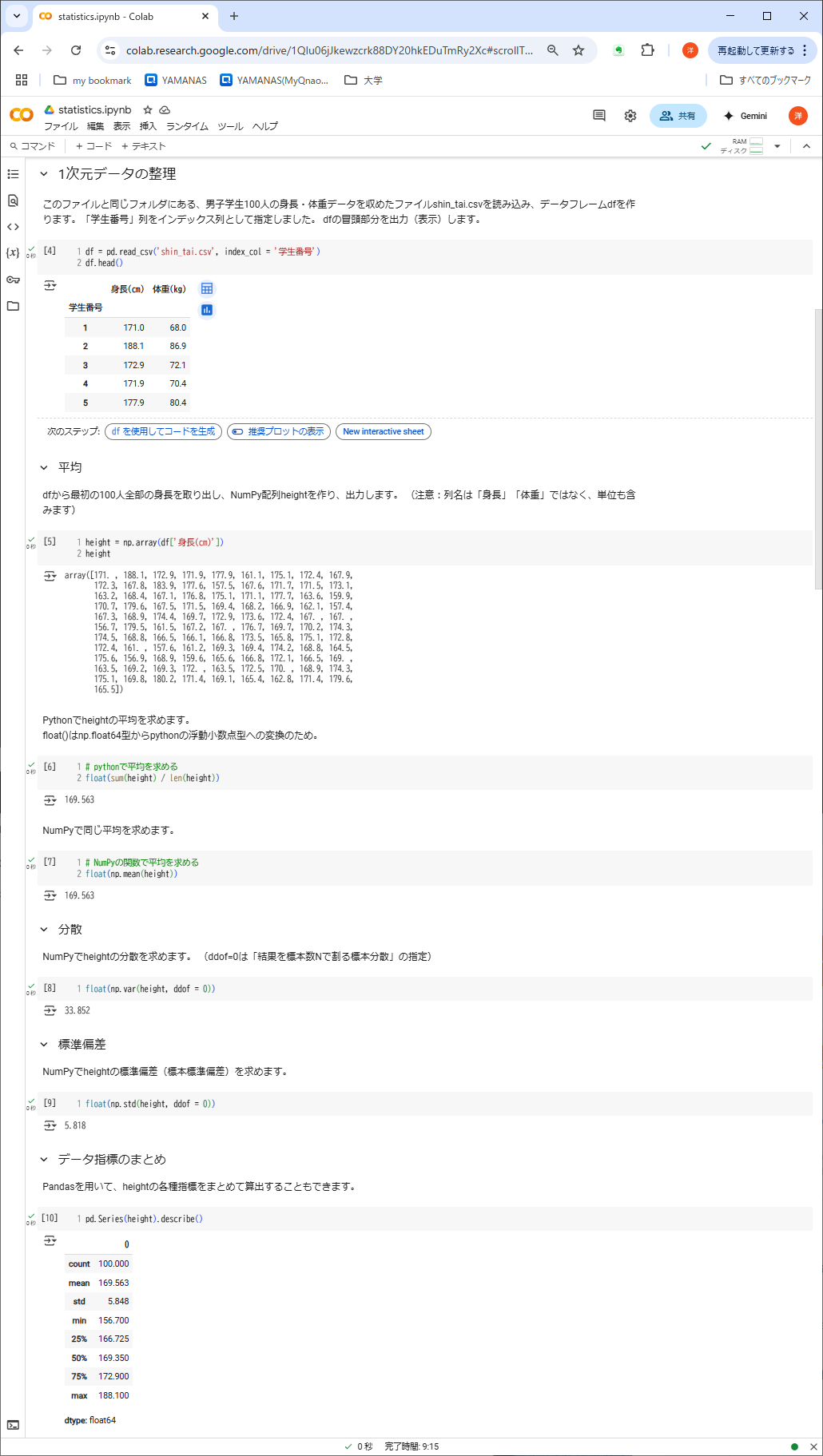
②の処理内容:1次元データの整理
- 100人の身長-体重データからデータフレームdfをつくる
- 身長だけをNumpy配列heightに取り出す
- その平均・分散・標準偏差を求める
- pd.Seriesでそれらを含む指標をまとめて算出する
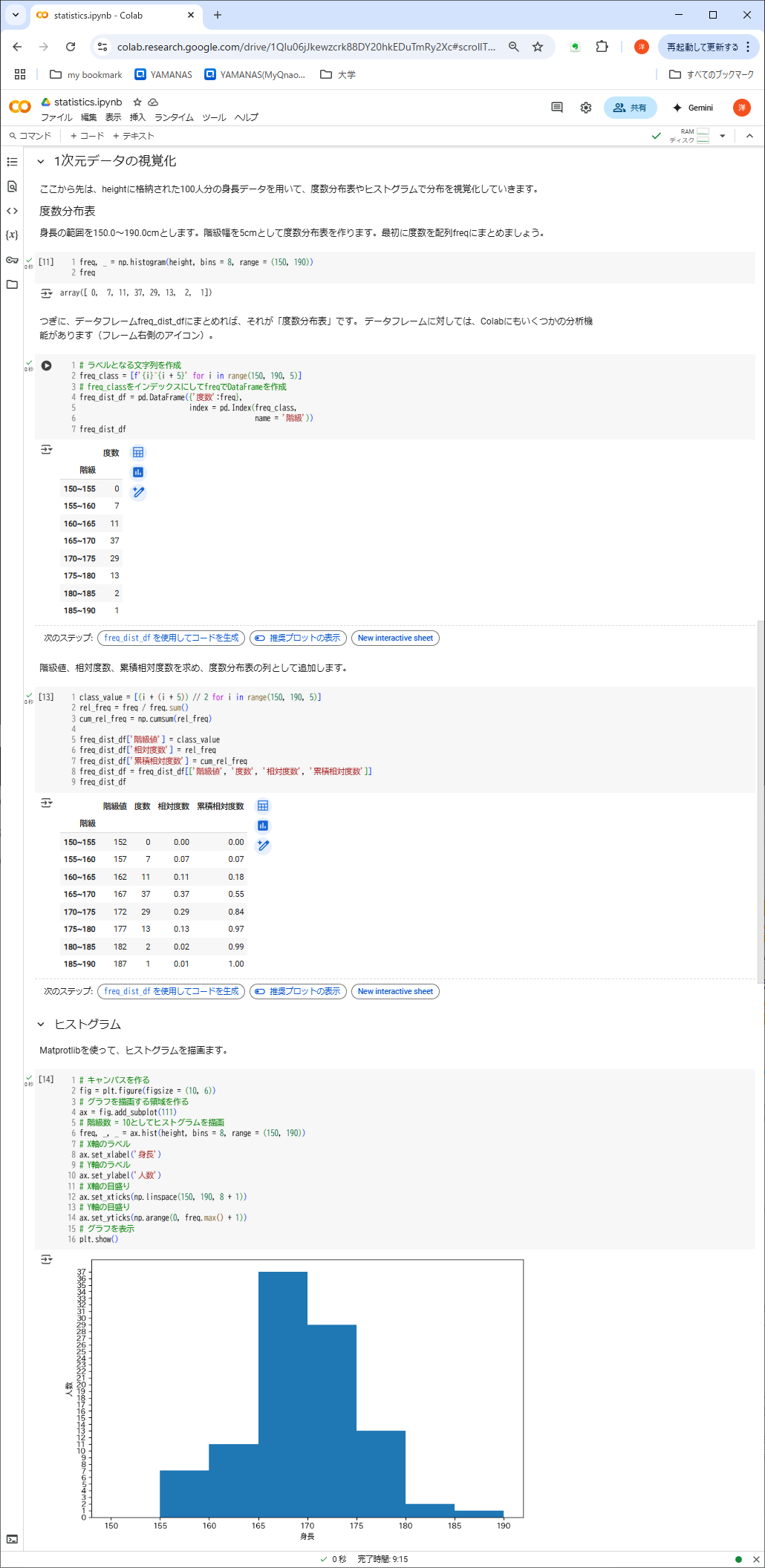
③の処理内容:1次元データの視覚化
- heightから配列freq、さらに度数分布表freq_dist_dfをつくる
- 度数分布表に階級値、相対度数、累積相対度数の列を追加
- Matprotlibを使って、ヒストグラムを描画
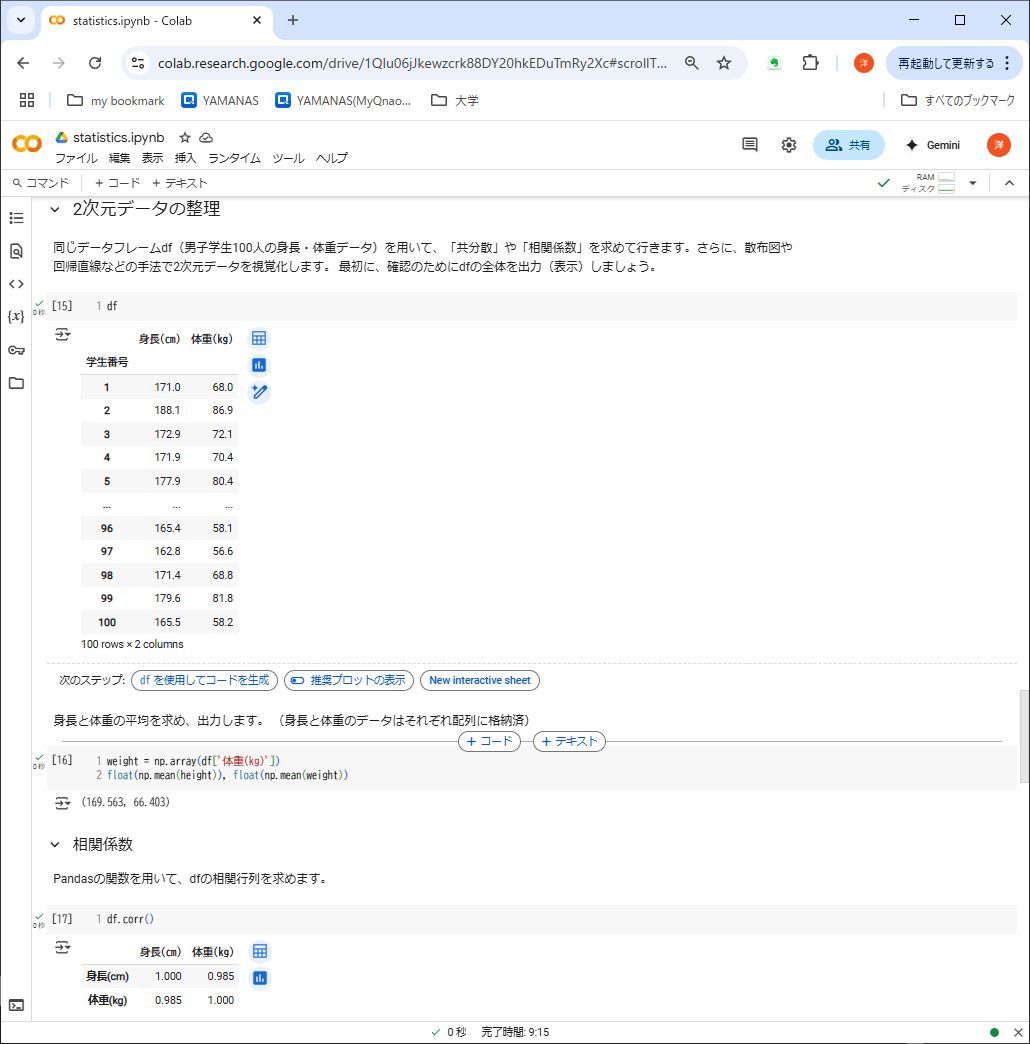
④の処理内容:2次元データの整理
- 100人の身長-体重データからつくったデータフレームdfを再度表示
- 体重の平均を算出する(身長の平均は②で算出済)
- 身長と体重の相関係数を表示
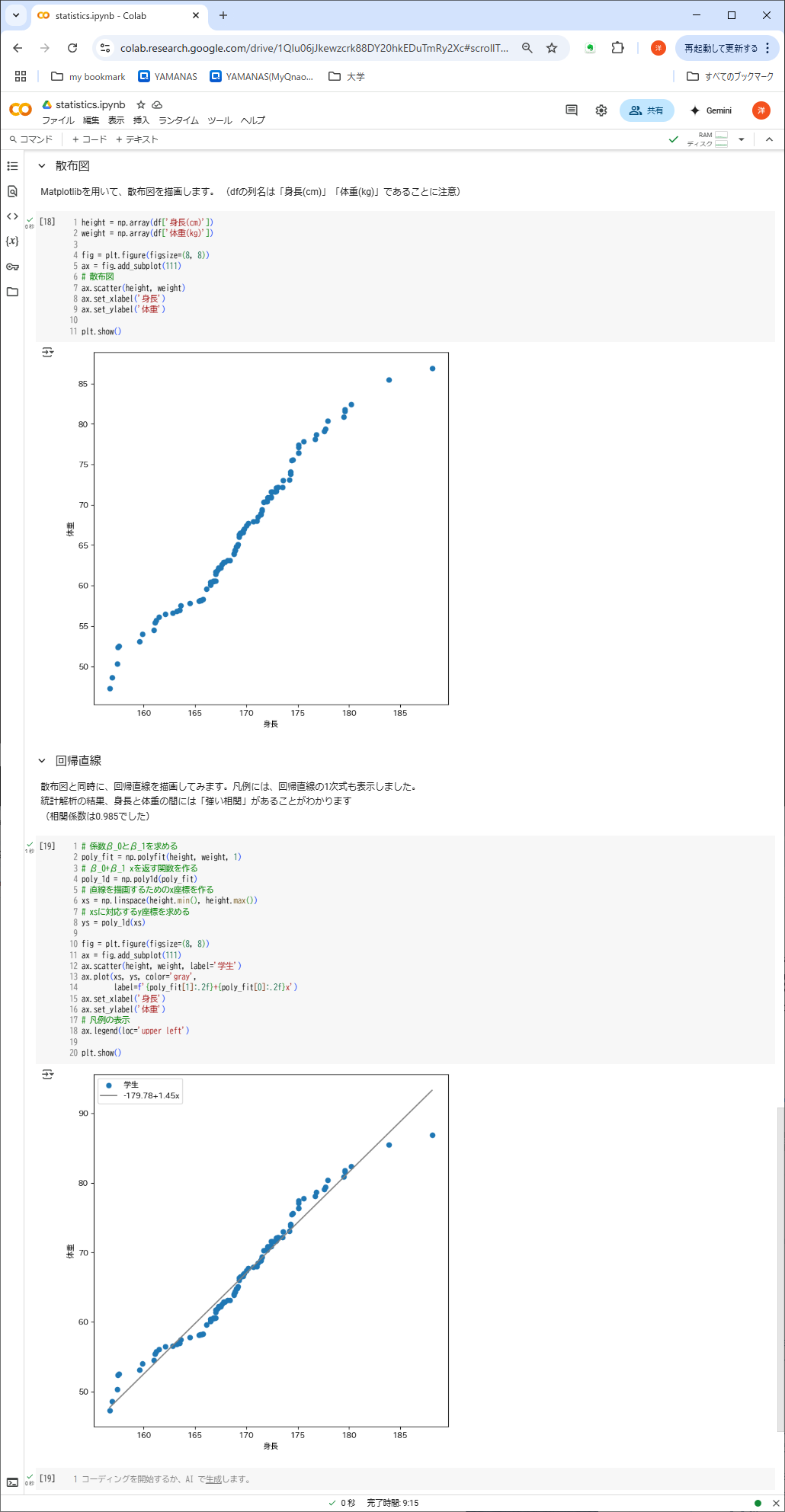
⑤の処理内容:2次元データの視覚化
- Matprotlibを使って、height, weightから散布図を描画
- 散布図に加えて回帰直線も描画
これで全部。新しいモジュールの機能をふんだんに使ったが、さほど難解とは感じられないのではないか。それに、統計解析の手順は、どんなデータに対してもいつも同じだから、このノートブックは(Excelのワークシートと異なり)いつでも再利用できる。必要なのは、新しいデータを格納したデータフレームかcsvファイルだけである。
このように、Excelではできなかった「処理手順と処理対象データの分離」が、Pythonと関連モジュールによって簡単かつ完全に実現した。みなさんの道具箱にも、ぜひこれらのツールを入れといてほしい。もちろん、ときどき手入れするのを忘れずに!
「プログラミング入門【python編】」を終えて
これで「プログラミング入門」の全カリキュラムは終了した。相当盛り沢山な内容になったので、みなさんにどこまで伝わったか、いささか不安だが、講義資料やサンプルプログラム、ビデオ教材にはいつでもアクセスできるので、理解があやふやなところは復習すればよい。
ここから先はいよいよ、自分のやりたいこと(コンピュータにさせたいこと)をプログラムとして表現する段階に進む。世界中の優秀で気前のよいプログラマたちが作ってくれたモジュールを駆使すれば、Pythonは短いプログラムで驚くべきことをしてのける実力を秘めている。
だが、せっかくここまで学んだプログラミング・スキルも、使わずに放って置けば、道具と同じで錆びついてしまう。ちょっとしたプログラムでよいから、自分で作って自分だけが得する体験を今後も積み重ねてほしい。
Have a nice coding! Be a pythonista!