第13回 正規表現
Pythonは汎用性の高い、何でも書ける言語だが、とりわけテキスト処理を得意とする。この点ではPerlやRubyの流れを汲む後継言語だといえる。今回は、テキスト処理のための最強機能である正規表現を学ぶ。
この回の内容
検索とは何か
そもそも検索とは何だろうか? 私たちはWebで情報を探したり、図書館で蔵書を検索したり、キーワードでなにかを探さない日はないほどだが、検索の定義を正確に他人に説明しろと言われると、ちょっと困るかもしれない。
図13-1に検索のモデルを示す。検索対象は、何らかの集合である。これを全体集合Sという。要素はどんなものでもよいが、正規表現の場合は文字列である。たとえばあるファイルのすべての行を考えればよい。
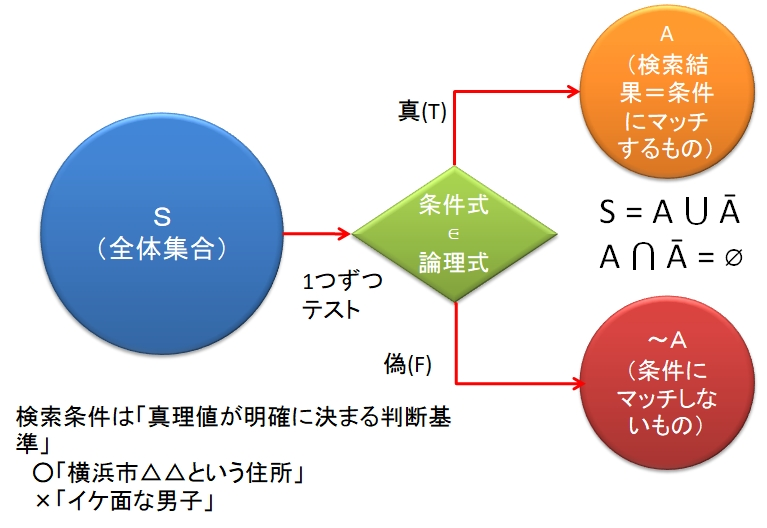
検索とは、全体集合Sに属するすべての要素を、検索条件を照らし合わせて、あてはまる(条件にマッチする)要素の集合A(検索結果)を取り出すことである。あてはまらない要素の集合は、補集合~Aである。
さらに形式的にいえば、
検索とは、全体集合Sを2つの部分集合Aと~Aに分割する操作である。
1 if文やwhile文の後に置く条件式の書き方にはもう慣れたであろう。Pythonを含む多くの言語では、真を「0以外の数」、偽を「0」と対応づける。また、条件式は真偽どちらかの値を必ずとるので、あいまいな条件ではいけない。
あいまい検索というあいまいな用語があるが、これは「記憶があいまいな時に用いる検索」とでも解釈すべきで、もちろん条件自体があいまいなわけではない。部分一致検索という用語を使うようにしよう。
正規表現によるテキスト検索
正規表現※2とは、特定の条件にマッチする文字列を検索したり、見つけ出した文字列(の一部)を別の文字列に置換する手段である。検索や置換の条件は正規表現パターンと呼ばれる定型文字列で表現される。パターンには特有の文法があり、これに慣れるにはちょっとした練習が必要だが、テキスト処理にはたいへん便利で強力な手段なので、ぜひ習得するべきだ。
正規表現はPythonだけの機能ではない。PERLでは言語の文法自体に正規表現が統合されているし、他の多くの言語でもライブラリとして利用できる。「秀丸」などのテキストエディタでも、検索や置換機能で正規表現を利用できる。
つまり、正規表現は、特定の言語やアプリとは独立な、テキスト処理のための汎用技術なのである。
2 英語ではregular expression。RE、regex、regex pattern、regexpなどさまざまに略記される。
正規表現パターン
正規表現が「最強」の検索ツールという意味は、それが全体集合Sを任意のAと~Aに分割する能力を持つからである。したがって、原理的にはすべての異なる検索を表現できる。だが、検索条件はたった1行の定型文字列(正規表現パターン)で表わされるので、複雑な検索には、そのぶん複雑なパターンを書く必要がある。求める検索に対応する正規表現を考えることは、ある意味でパズルを解くのに似ている。
正規表現の実習にあたっては、ちょっと準備が必要だ。検索対象の(つまり全体集合Sにあたる)テキストファイルが必要だからである。授業フォルダに置いておくので、Colabノートブックと同じいつものディレクトリ(マイドライブ/Colab Notebooks)にアップロードしておくこと。
- あいさつ(greetings.txt)
Good Morning! Hello! Good Bye! Thank You! Good Night! - SPEED(speed.txt)
Hiroko Shimabukuro Eriko Imai Takako Uehara Hitoe Arakaki - 人名(people.txt)
Michel Jackson Janet Jackson Joe Jackson Joni Mitchel Jackson 5 Micheal Johnson Jon Anderson Sade Hiroko Shimabukuro Eriko Imai Takako Uehara Hitoe Arakaki John Paul Jones 14 carats souL Prince UK US3
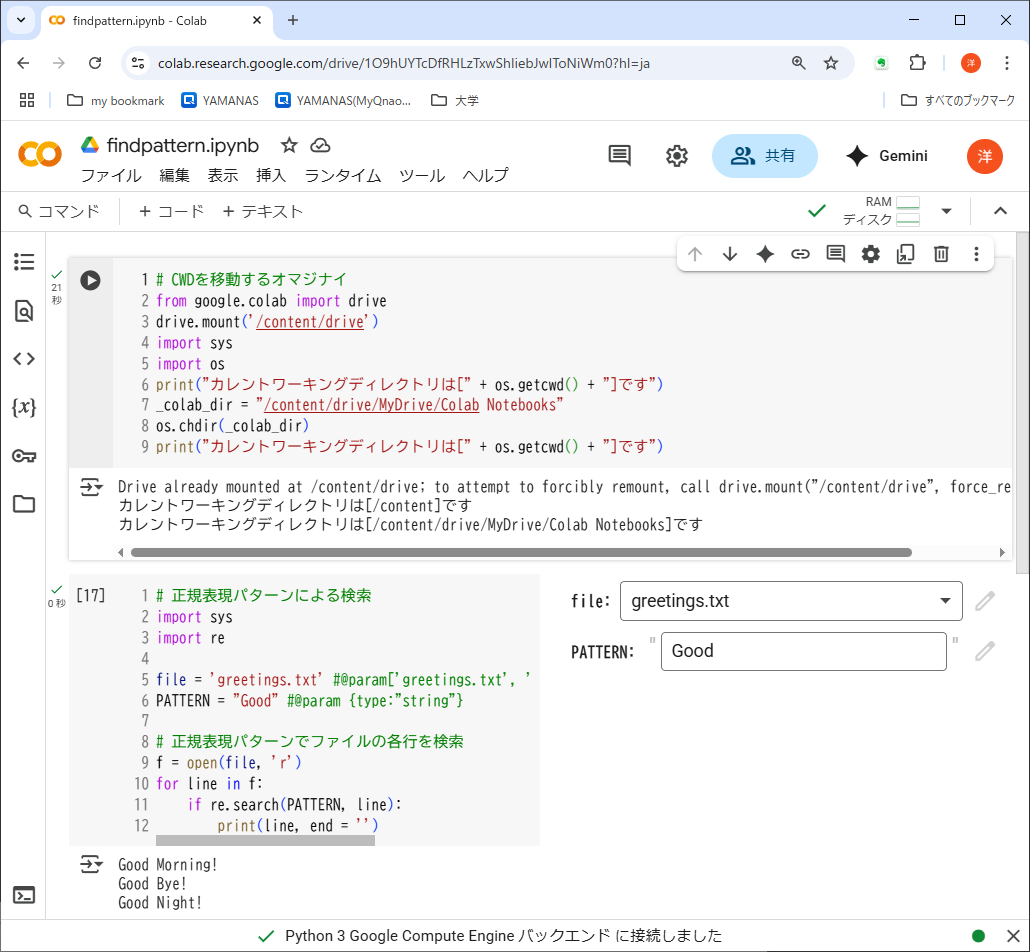
正規表現を利用するには、モジュールreをimportする※3。
3 Perlは言語の構文として直接、正規表現をサポートしている。こうした言語は稀だが、テキスト処理に強いと言われる所以でもある。だが、Pythonを学んだ皆さんが、Perlに戻る必要はほとんどない。
正規表現パターンは'Good'である。単なる文字列だが、これもパターンの基本的な形態であり、「検索条件」に相当する。
関数re.search(pattern, line):が条件判定(パターンマッチング)を実行する。ファイルの各行を正規表現パターンと比較して、マッチ(適合)すれば真を返す。
このプログラムをテストするには、コードセル右側のプルダウンメニューやテキストボックスでファイル名とパターンを入力して実行すればよい。これらのUIは、プログラム中の「#@param」以下の注釈によって生成されている。この機能を「Colabフォーム」といい、このような、一部を書き換えて繰り返し実行するプログラムには便利なので、ここで紹介しておく。
しかし、これはColab特有の機能で、他の環境では使えないし、コードセル内のプログラムを直接書き換える点で、通常のUIとは動作が異なるので、この授業ではここだけの紹介に留める※4。
4 PCプラットフォームで実行するプログラムなら、入力リダイレクトを使ってつぎのコマンド行を実行するのが常道であり、ファイルをいちいちopenしないだろう。
python findpattern.py < greetings.txt
今回は、正規表現パターンを理解するのが目的の授業だし、「Colabフォーム」の使い方に興味のある人もいるだろうから、コピペ可能な形式でコードを挙げておく。リスト13-1の最初のコードセルは、CWDを移動するいつものオマジナイなので、第6回の講義資料からコピペすればよい。
# 正規表現パターンによる検索
import sys
import re
file = 'greetings.txt' #@param['greetings.txt', 'speed.txt', 'people.txt']
PATTERN = 'Good' #@param {type:"string"}
# 正規表現パターンでファイルの各行を検索
f = open(file, 'r')
for line in f:
if re.search(PATTERN, line):
print(line, end = '')
だが、このような単純な判定なら、そもそも正規表現を持ち出すまでもなく、たとえば、
if line.count('Good'):
正規表現の簡単なまとめ
この講義資料で、正規表現パターンのすべてを説明することは、とてもできない。正規表現という技術はそれほど大規模で奥が深い。下の5つの表にまとめた事柄以外は、python言語リファレンスの「正規表現 HOWTO」を参考にしてほしい※5。
5 αからΩまで知りたい人には、「決定版」ともいえる有名な本『詳説 正規表現 第3版』 Jeffrey E.F. Friedl オライリー・ジャパンもあるが、別に奥義を極めなければプログラムが書けないわけじゃない。多少難解だろうと、1行の正規表現パターンをひねり出すのと、if文の山を築くのと、どちらがいいですかというだけの話だ。
文字や文字クラス
これらは1文字にマッチする。
| 記号 | 意味 | 使用例 |
|---|---|---|
| . | 任意の1文字 | .+ |
| \w | 英数字(アルファベット、数字、アンダスコア( _ )) | \w+ |
| \W | 英数字以外 | |
| \d | 数字 | \d{3}-\d{4} |
| \D | 数字以外 | |
| \s | 空白文字(半角スペース、タブ、改行) | \s+ |
| \S | 空白文字以外 | \S+\s+\S+ |
| \n | 改行文字 | |
| \t | タブ | |
| \\ | \記号 | |
| [ ~ ] | [ ]の中のどれか1文字※1 | [abc] [A-Z] [0-9] |
| [^ ~ ] | [ ]の中に無い1文字※1 | [^0-9] [^a-z] |
文字列に対する指定
文字の並びを選択するための記法。
| 記号 | 意味 | 使用例 |
|---|---|---|
| ( ~ ) | ( )内を量指定子の対象とする | su(mo){2,} |
| ( ~ | … ) | ~または… | (AKB|NMB)48 |
表注1 文字クラスの[ ]内で正規表現は使えない。
量指定子
文字の後に置いて、繰り返し回数を指定する。
| 記号 | 意味 | 使用例 |
|---|---|---|
| * | 直前の文字の0回以上の繰り返し※2 | |
| + | 直前の文字の1回以上の繰り返し※2 | \w+ |
| ? | 0回または1回(つまり直前の文字は省略可能)※2 | 非?対称 |
| *? | 直前の文字の0回以上の繰り返し※3 | |
| +? | 直前の文字の1回以上の繰り返し※3 | |
| ?? | 0回または1回(つまり直前の文字は省略可能)※3 | |
| {n} | 直前の文字のn回の繰り返し | \w{4} |
| {n,m} | 直前の文字のn回以上m回以下の繰り返し(n,mの一方は省略可)※2 | A{1,3} |
| {n,m}? | 直前の文字のn回以上m回以下の繰り返し(n,mの一方は省略可)※3 |
表注2 最長マッチ。条件に合う最も長い部分にマッチする。
表注3 最短マッチ。条件に合う最も短い部分にマッチする。
位置指定子
「特定の文字」ではなく「特定の位置」にマッチする。アンカーともいう。
| 記号 | 意味 |
|---|---|
| ^ | 行の先頭 |
| $ | 行の末尾 |
| \< | 単語の先頭 |
| \> | 単語の末尾 |
| \b | 単語の先頭か末尾(単語境界) |
| \B | 単語の先頭、末尾以外 |
| \A | ファイルの先頭 |
| \z | ファイルの末尾 |
| \G | 直前のマッチ文字列の末尾 |
置換文字列中で使える表記
「マッチした文字列」を表す表現。これらは正規表現ではない。
| 記号 | 意味 |
|---|---|
| \0 | マッチした文字列全体 |
| \1 \2 … \9 | 検索文字列の1~9番目の ( ) にマッチした文字列 |
| \l | 次の1文字を小文字にする |
| \L ~ \E | 挟まれた文字列を小文字にする |
| \u | 次の1文字を大文字にする |
| \U ~ \E | 挟まれた文字列を大文字にする |
| \n | 改行 |
| \t | タブ |
| \\ | \記号 |
演習:パターンを使ったさまざまな検索
リスト8-1のプログラム「findpattern.ipynb」で、正規表現パターンを書き換えながら、つぎのような検索をしてみよう。対象ファイルは「people.txt」である。Colabフォームに入力したパターン文字列が化けたり(例:\ → \)、コードセル内でさらに変化する(例:\ → \\)かもしれないが、結果に影響はないので驚かなくてよい。
- 苗字がJacksonの人
- Jで始まる人。グループ名などは除く
- 1語の名前
- 3語の名前
正規表現によるテキスト置換
正規表現は、文字列を検索するだけでなく、検索で発見された部分を他の文字列に置換するのにも使える。ただし置換用のパターンは、検索用のパターンと一部異なる。それは、パターンの一部にマッチした入力文字列の一部を記憶しておき、置換文字列の一部として指定しなければならないからである。
そのために、( )と、\1,\2などの特殊文字を用いる(前掲の表「置換文字列中で使える表記」を参照)。
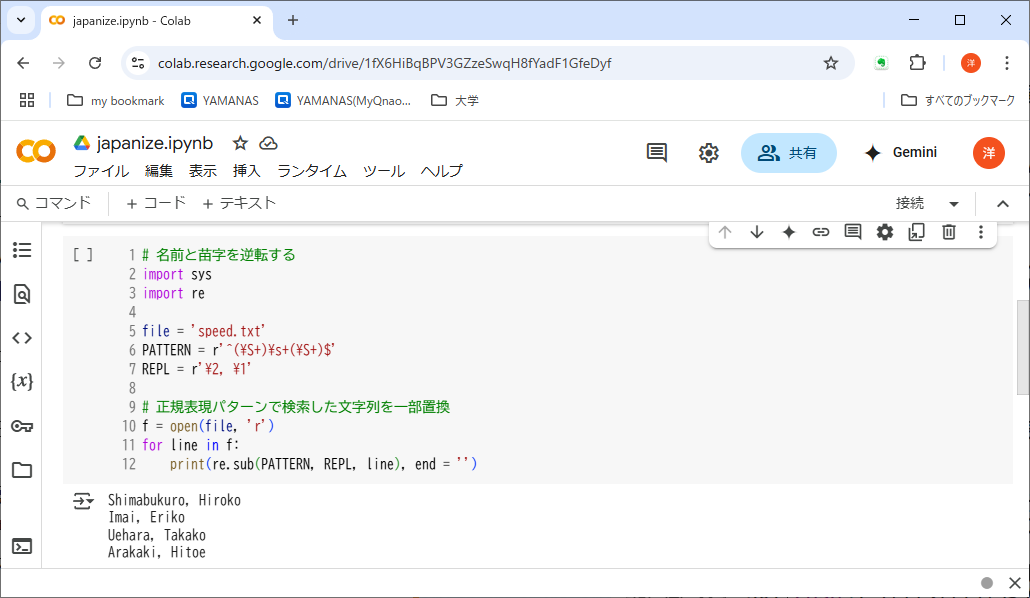
リスト13-2のプログラムは、英語表記の名前と姓を(日本風に)逆転して出力する。ファイル「speed.txt」で動作を確認しよう。
実際に置換を行うのはメソッドre.subである。第1引数の正規表現パターン(PATTERN)中で、( )内にマッチした文字列が、先頭から順番に記憶され、第2引数の置換文字列(REPL)中で\1, \2 ...の位置に展開されることで、具体的な置換が行なわれる。
( )と番号は、出現順に対応づけられる。この例では、\1に名前が、\2に苗字が対応する。
PATTERNとREPLに代入した引用符の直前の文字「r」は、raw文字列の指定で、文字列に含まれる特殊文字の働きを抑止する。パターンが特殊文字を含まなければ不要だが、一般に正規表現パターンや置換文字列は特殊文字をふんだんに含むので、r指定する習慣をつけたい※6。
6 リスト13-1において、PATTERNに代入する文字列定数を「r指定」しなかったのは、Colabフォームのテキストボックスと干渉して誤動作したからだ。Colabフォームはやはり慎重に使うべきだ。
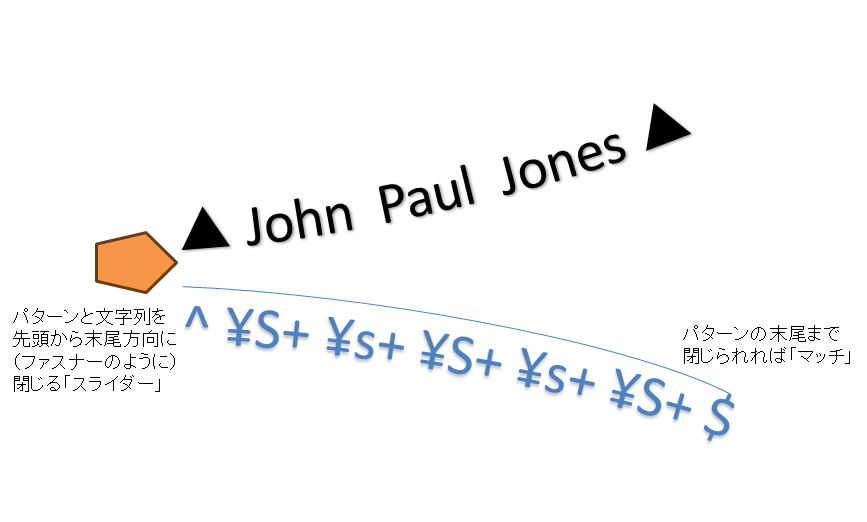
パターンマッチングのしくみ
正規表現パターンと対象文字列とのマッチングは、どんなしくみで行われるのか? 図13-2に模式図を示す。対象文字列は黒、正規表現パターンは青で表している。
演習:スケジュール管理ツールの入力チェック
せっかく正規表現という最強ツールを使えるのだから、実用アプリに必須の入力チェックに応用してみよう。
第11・12回でつくったスケジュール管理ツールには、日付や時刻を入力する部分がいくつかあるが、その形式が辞書yoteiのキーと合致しないと正しく検索できない。
たとえば、新たなスケジュールの「登録」コマンドは、以下の構成になると予想されるが、本来ならユーザーが入力した日付と時刻の形式チェック処理が必要である。形式が不適切ならメッセージを表示してコマンドを終了すべきだ(メインメニューに戻る)。その処理を各コマンドの必要な位置に挿入すること。
# 登録コマンド
def 登録(yotei):
日付 = input('登録する日付を入力 例)2025-03-14:')
# ← 不適切な日付のチェック処理
時刻 = input('登録する時刻を入力 例)09:30:')
# ← 不適切な時刻のチェック処理
登録日時 = f'{日付} {時刻}'
:
:
yotei[登録日時] = 予定
print(f'1件の予定を登録しました {予定表示(予定)}')