第8回 データ構造(集合・ディクショナリ)
第5回では、多くのデータをつぎつぎに処理するためのデータ構造として、リストを学んだ。しかし、Pythonに備わるデータ構造はリストだけではない。今回は集合とディクショナリ(辞書)について学ぶ。
この回の内容
集合
リストは複数の値を1つの名前で格納できる便利なデータ構造で、これなしには本格的なプログラムは書けない。そもそも、プログラムは多数のデータを次々に処理するためのものだから、必要性・重要性は明らかだ。
だが、複数の値を格納できるデータ構造はリスト(やタプル)だけではなく、Pythonにはさらに
- 集合
- ディクショナリ(辞書)
集合の性質
これまでの授業では、学校数学とICTの道具立ての相違を強調してきたが、集合(set)は数学の「集合」概念に近い。リストが複数の値を順序をもつ列として格納し、インデックスという整数でアクセスするのに対し、集合は複数の値を順序も重複もない集まりとして格納する。順序がないのだから、当然インデックスによるアクセスもできない。値(要素)の追加と削除、集合に含まれるかの判定のような基本的な集合操作と、数学的な集合演算、すなわち和、交差、差などがあるだけだ。
リスト8-1のプログラムで、集合の性質を確かめよう。
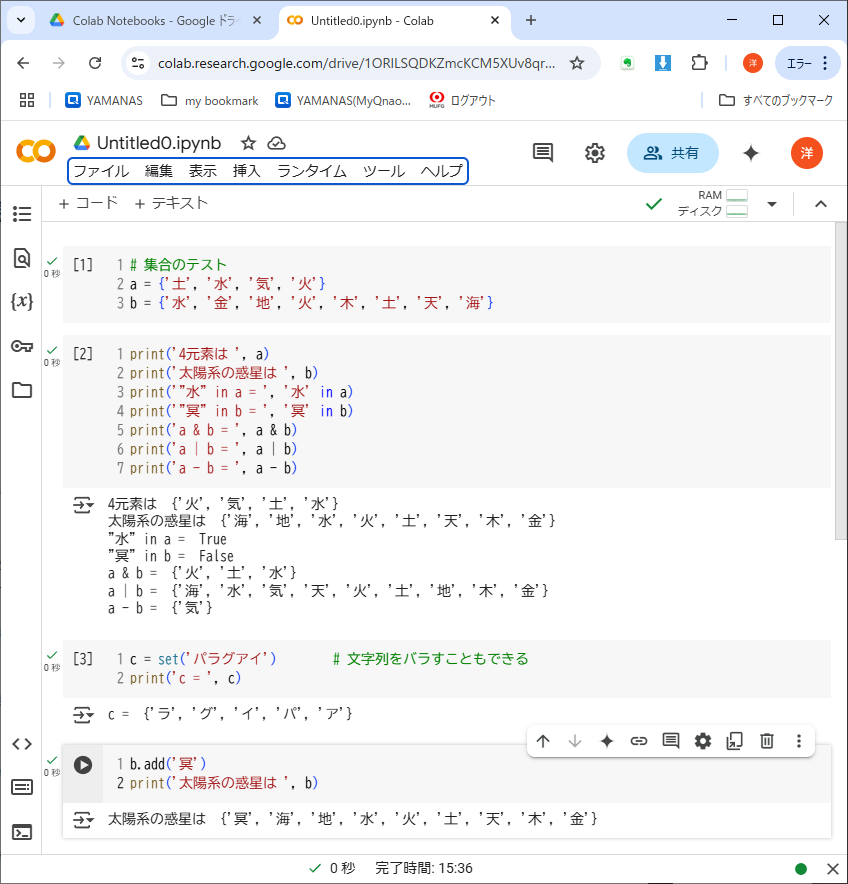
[1]のコードセルで、a(4大元素)とb(太陽系の惑星)という2つの集合を定義している。それぞれの要素は漢字1文字の文字列だが、全体を大括弧[]ではなく中括弧{}で囲んでいることに注意しよう。
a = ['土', '水', '気', '火']
ならば、もちろんリストになる。
[2]のコードセルでは、集合に対して各種操作をしている。
-
要素が集合に含まれるかのテスト
積・和・差集合
最後のコードセル([4]の表示が隠れている)では、集合bに新たな要素'冥'を追加している※1。
1 私が子どものころ、「冥王星」は太陽系の惑星の仲間だったのに、いつの間にか「準惑星」に格下げされてしまった。
ディクショナリ(辞書)
集合は、ある値が含まれるかの判定には便利だが、インデックスによるアクセスができないため、使用場面はリストより限られる。
それに対し、リスト以上の有用性をもつデータ構造がディクショナリ(辞書)である。その名の通り文字列をインデックスとして個々の要素にアクセスできる。他の言語(たとえばPerl)ではハッシュとか連想配列という名前で実装されている。
従来のデータ構造であるスカラーやリストとの違いを、図8-1に示す。
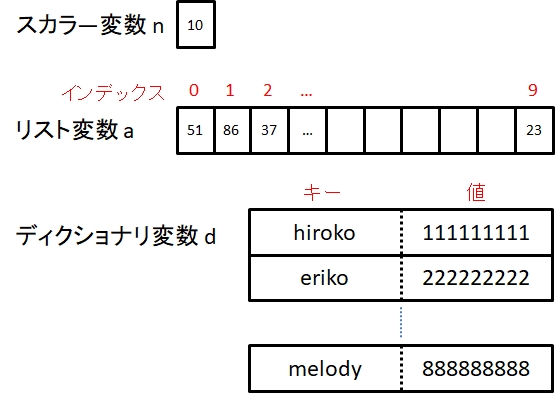
「キー:値」ペア
さっそくディクショナリを1つ作ってみよう。これは電話帳に見立てたデータを格納している(リスト8-2)。「:」の左側('hiroko', 'eriko', ……)は、ディクショナリの要素にアクセスするための文字列で、キーという。「:」の右側('11111111', '2222222', ……)はキーによってアクセスされる要素で、値という。
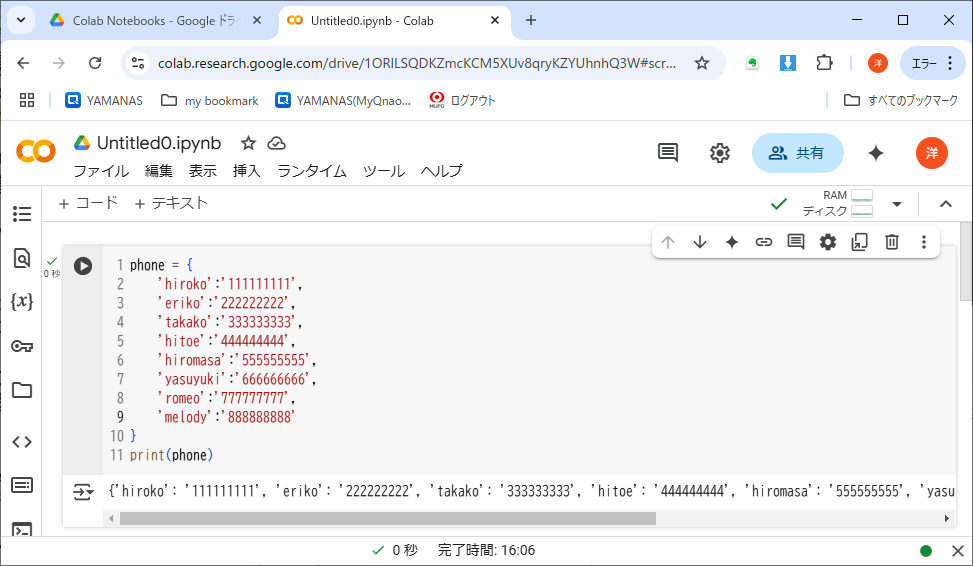
つまりディクショナリは、「キー:値」の組(key-value pair)を複数格納した集合のようなものだ。実際、初期化構文の外側は集合と同じ{}で囲まれている※2。
2 「集合のようなもの」とは歯切れが悪いが、厳密には少し異なる。「キー:値」の組全体として重複を許さないのではなく、値は重複してもよいが、キーは単独で重複できない。また、phoneはキーも値も文字列として定義されているが、キーはタプルでもよく、値はなんでもよい(たとえば、別のディクショナリも格納できる)。実に強力で柔軟なデータ構造だ。
ディクショナリの初期化構文には、もう1つ別の形式もある。リスト5-6の形式だと、キーの文字列を囲む「''(シングルクオート)」が煩雑な感じだが、それを省略してリスト8-3の形式でも書ける。
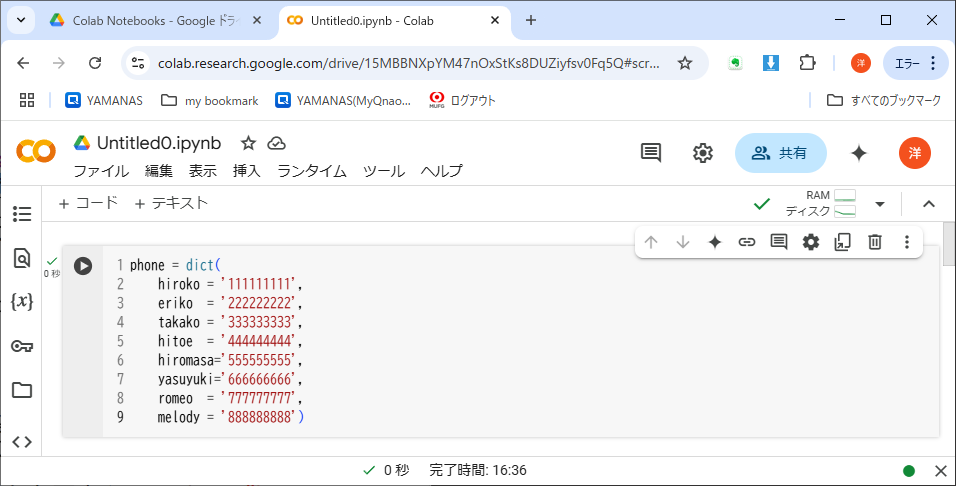
値の方を囲む「''」は省略できないが、半減しただけでも見た目スッキリする※3。
3 見た目スッキリはいいけれど、この姿はどこか奇妙である。まるで、ディクショナリを生成する関数dict()に、hirokoやeriko、その他あらゆる可能な文字列のオプション引数が定義されているように映る。もちろんそんなわけはないが、学習が進むと分かるのは、どうやら関数のオプション引数という仕組みと、ディクショナリとは、裏の方でズブズブの関係にあるらしいことだ。ここではこれ以上深入りしない。
ディクショナリがリストより有用な場面は多い。たとえば人名に対して、電話番号や住所などの個人情報を格納し検索する、アドレス帳のようなアプリケーションを考えよう。リストでこれを実現するには、
- 人名を格納したリストを先頭から探し、インデックスを突き止める。なければその人の個人情報は格納されていない。
- そのインデックスで、別のリストにアクセスし、個人情報を取り出す。
また、ディクショナリは永続的記憶(アプリケーションが終了してもデータを保持できる仕組)である(データベース(DB)ともたいへん相性がよい。Pythonにも、ディクショナリのデータを永続化する手段がいくつか存在する。この授業の課題として作成する「ToDoリスト」でも、データの永続化は中心課題だ。このように、ディクショナリは本格的なDB利用アプリへの架け橋だから、しっかり理解しよう。
人名から電話番号を返す
せっかく電話帳(もどき)のディクショナリを定義したのだから、電話帳検索ツールも作ってみよう。リスト8-3に、もう1つコードセルを追加して実行すると、簡易電話帳として動作するはずだ。
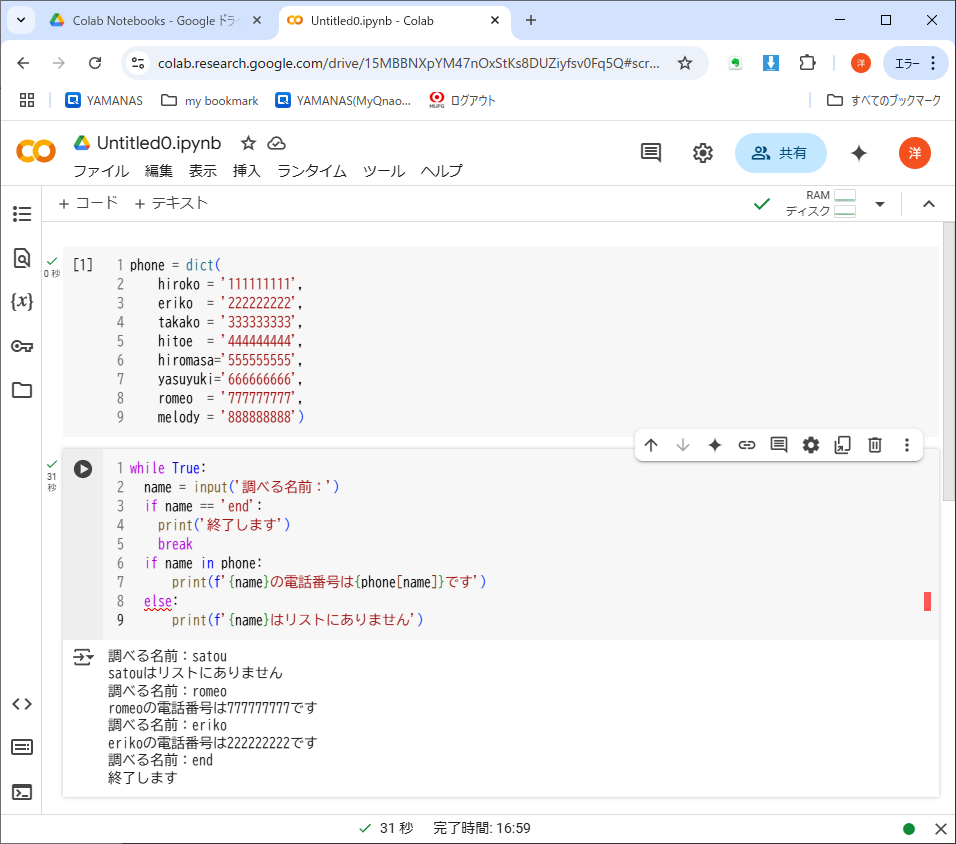
input()関数によってユーザが入力した名前から、ディクショナリphoneを検索し、ヒットすれば電話番号を返す。なければ「リストにありません」と答えるだけの簡単なプログラムである。名前の代わりに「end」と入力すると、無限ループから脱出してプログラムを終了する。
データ構造とforループ
リスト・集合・ディクショナリと、Pythonのデータ構造が出揃ったところで、それらの要素へのアクセス方法をまとめておく。スカラ変数では変数名を書くだけだが、1つの名前でいくつもの値を格納するこれらのデータ構造は、それぞれアクセス方法が異なるからだ。リスト8-5に相違をまとめた。
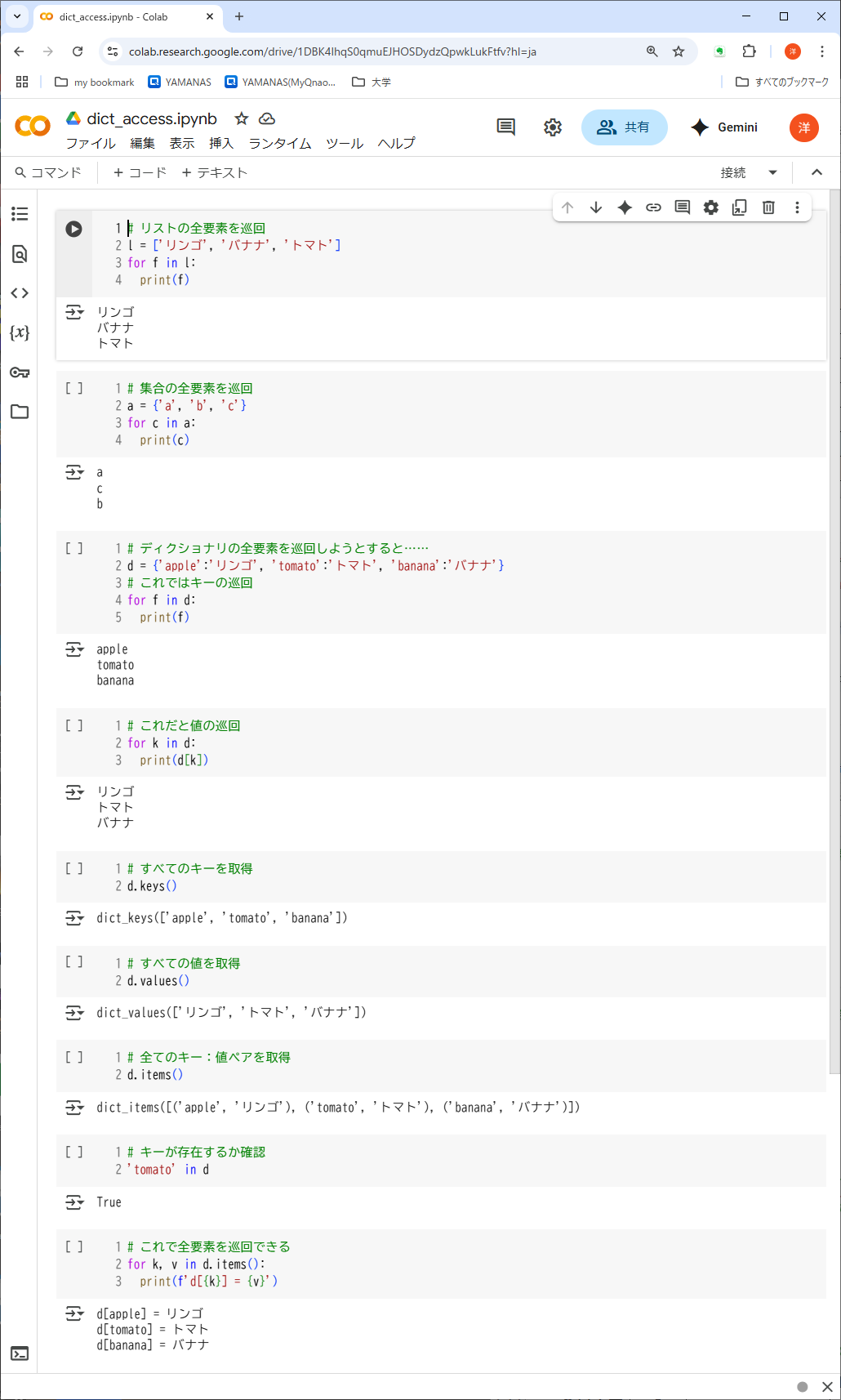
- リスト
- インデックスがあり、要素の順序もあるので、単純なfor文で全要素を巡回(列挙)できる
- 集合
- 単純なfor文で全要素を巡回できるが、取り出される順番は一定しないことに注意
- ディクショナリ
- キーと値の区別がある分、他のデータ構造より複雑である。単純なfor文では、キーの巡回ができるだけだ。キーによってディクショナリにアクセスすれば、値の巡回になってしまう
4 もちろん私がそう呼んでいるだけだから、他所でこんな名前を使うと恥をかく。
- keys()
- ディクショナリのすべてのキーを返す。値は特殊なdict_keysオブジェクトだが、for文でリストと同様に巡回でき、list()関数でリスト化もできる
- values()
- ディクショナリのすべての値を返す。 値はやはり特殊なdict_valuesオブジェクトだが、dict_keysと同様に扱える
- items()
- ディクショナリのすべての「キー:値」ペアをタプルにして返す。keys()とvalues()の値の順序は一般に一致しないので、このメソッドの存在価値は大きい。値はやはり特殊なdict_itemsオブジェクトだが、dict_keysと同様に扱える
すべてのキーと値を巡回するには、items()を使って最後のコードセルのように書く。items()の各要素はタプルなので、forの直後の「k, v」だけで、キーと値の両方を対応したまま代入できる。以前の回でPythonのあちこちでタプルが暗躍しているといった実例の1つだ。
keys(), values(), items()の「メソッド三羽烏」は、ディクショナリの活用に欠かせないので、ぜひここでマスターしよう。
売り上げ計算プログラム
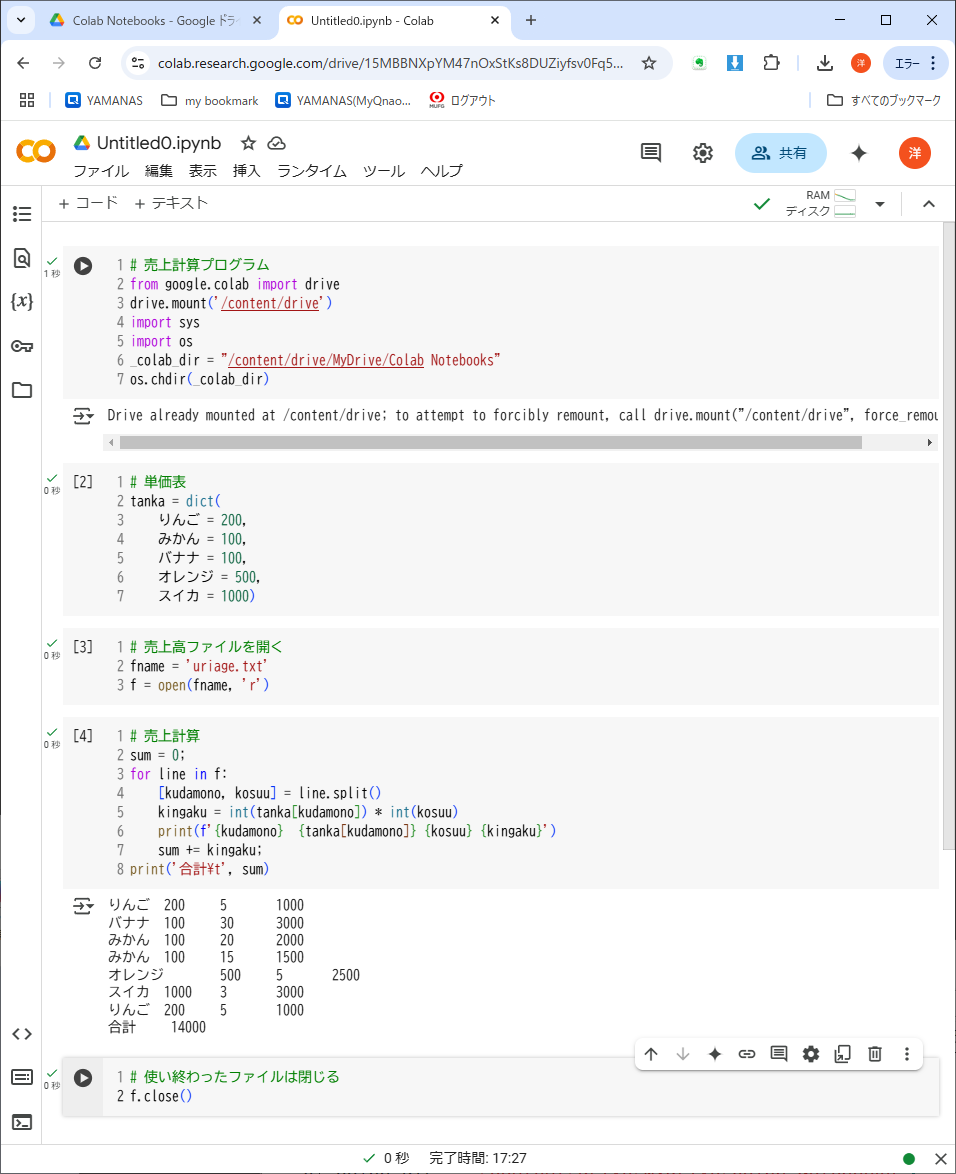
ディクショナリを使って、もう少し複雑なプログラムを書いてみよう。果物屋の売り上げを計算するプログラムだ。
果物の単価表は、プログラムの冒頭で定義されている(tankaディクショナリ)。
果物の売上高ファイルは、授業フォルダからダウンロードできるので、いつものように、ノートブックと同じ「MyDrive/Colab Notebooks」にアップロードしておく。
最初のコードセルは、「カレントディレクトリ(CWD)」を移動するいつもの「オマジナイ」で、Colabでしか使えないコードだから、第6回の講義資料からコピペするとよい。
各コードセルにプログラムを入力し、上から順に実行すると、リスト8-6の通りに売上高(合計14,000円)が計算できるはずだ。
演習:「単価表」のファイル化(外部化)
売上高だけでなく、単価表データも外部のテキストファイルから読むようにしたい。手順は以下の通りである。
- 単価表ファイルは、授業フォルダからダウンロードして、ノートブックと同じフォルダにアップロードしておく
- Colabに表示されている単価表のコードセル(リスト5-9では[2])を削除する。
- 代わりに空の単価表ディクショナリを作るために、以下のコードを同じ位置に挿入する。
tanka = dict() - その下にコードセルを追加し、単価表ファイルから値を読み込んでtankaディクショナリに格納してから売上高を計算するように、リスト8-5のプログラムを書き換える
- 上のセルから順に実行する