第6回 ファイルからの入出力(open, readline, print, close)
プログラムは通常、データを受け取って処理を行い、結果を表示する。正常に処理が行われなかった場合にはエラーメッセージも表示する。これらをまとめて、プログラムによるデータの入出力という。
この回の内容
Colabにおける通常の入出力
ColabのプログラムはChromeブラウザ上で実行される。ユーザからの入力はinput()関数などによりキーボードから行われ、出力はコードセルの下に「出力アクション」として表示される。
これはローカルPC上で実行されるプログラムとはやや異なる。よい機会なので、Colab上のプログラムと、ローカルPCで実行されるプログラムの違いについて理解しよう。
Colabのプログラムは以下のような特徴をもつ。
- プログラムがローカルPCではなくColabサーバ上で実行される。つまりPCプラットフォーム上のプログラムではなく、クラウドプラットフォーム(またはWebプラットフォーム)上のプログラムである
- Googleドライブ上のディレクトリ(この授業では/content/drive/MyDrive/Colab Notebooks)上のファイルにしかアクセスできない。処理対象のファイルはあらかじめ上記ディレクトリにアップロードしておく必要がある
- ブラウザ外に表示されるGUIが作れない。細かい設定を要する実用ツールや、ヌルヌル動くアクションゲームは作りにくい
- コマンドラインの概念がない。プログラムの外部からパラメータを渡す場合、input()などの入力関数を使うのが主になる
- 標準入出力や入出力リダイレクトの概念もない。これらはPythonというよりOSの機能だが、これらが使える環境なら明示的にファイルをオープンする必要はかなり少なくなる。逆にColab上ではファイルからの入出力が重要な機能になってくる
1の特徴は、クラウドないしWebプログラミングへの移行というソフトウェアの進化に沿ったものだから、これからのプログラマには必須の知識である。2と3は、主としてセキュリティ上の要請。4と5は、プログラムが具体的なOSを介さずに実行されるための制限である。
ただし、これらの違いを知って使えば、Colabは学習むけの環境で、実用的プログラムは無理といった、よくある誤解は生じない。
リスト6-1に、第3回の授業で学んだhello.ipynbのプログラムを再掲する。これは簡単ながら、データの入力と出力の両方を含んでいた。
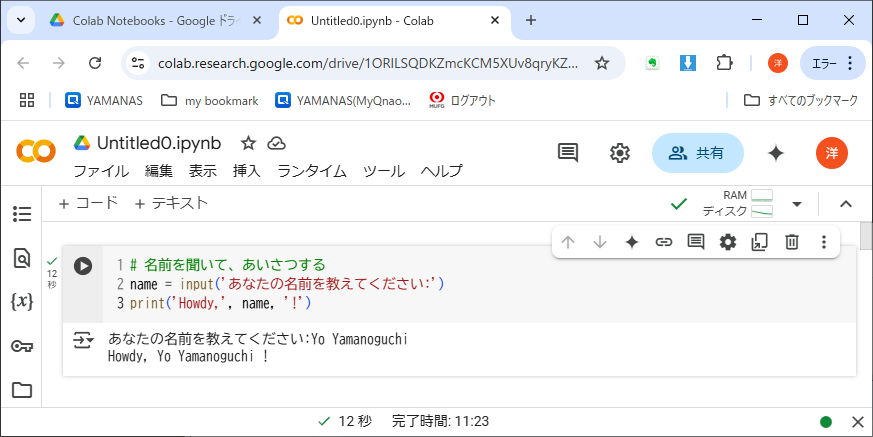
2度目だから、プログラムの動作を簡単に解説しよう。
- プログラムの入力動作
- 最初に実行されるinput()関数は、引数として渡されたプロンプト文「あなたの名前を教えてください:」を画面(コードセルの出力アクション)に表示する。これはユーザに入力を促すための文である。実際にユーザが自分の名前を入力するまで、プログラムの「実行点」はinput()関数から出ない。入力された名前は、変数nameに文字列として代入される
- プログラムの出力動作
- 実行点は次のprint()関数に移る。これは副作用としてデータを画面に出力(表示)する。引数は、文字列定数の列であり、print()関数は引数として渡されたデータ('Howdy', name, '!')を順に連結して出力する。Colab環境の場合、出力先はコードセルの出力アクションである
- ユーザの入力を促す文(プロンプト)を出力
- ユーザに名前文字列を入力させ、変数nameに格納
- その名前を織り込んだあいさつ文を出力
以上がColab環境でのデータ入出力の基本である。PCプラットフォームのように、標準入力・標準出力といった入出力先や、文字コードの種類(エンコーディング)を意識する必要はまずない(これは利点でも欠点でもある)。
ファイルからの入出力
ファイルのオープンとクローズ
プログラムの処理対象は、名前やあいさつ文といった短いデータに限らない。それどころか、学習用のサンプルプログラムを除けば、そうした場合はむしろ稀である。
キーボードから入力できるデータ量はたかだか数行程度だ。より多量のテキストデータを入力するには、テキストファイルからの入力など、別の方式によるしかない。また、テキストではないバイナリデータの場合は、量に関係なくキーボードでは入力できない。
出力データの場合も同様だ。たかだか数行程度の出力なら、画面に表示するだけでよいかもしれないが、より多量のテキストデータを出力する処理だと、出力結果をファイルに保存するニーズが生ずる。
そこでこの単元では、明示的にファイルを開き(open)、入力をキーボードではなくファイルから受け取ったり、出力を画面表示ではなくファイルに保存する方法を学ぶ※1。
1 PCプラットフォームのプログラムだと、OSに備わっている入出力リダイレクトの機能を用いて、明示的なファイル操作なしに入出力先をファイルに振り向ける(redirect)ことができる。
リスト6-2に、入力ファイルの各行の先頭に行番号をつけて出力するプログラムの例をを示す。ここでは、ファイルの使い方を説明するために、あえて古風な繰り返し構文(while)を使っている。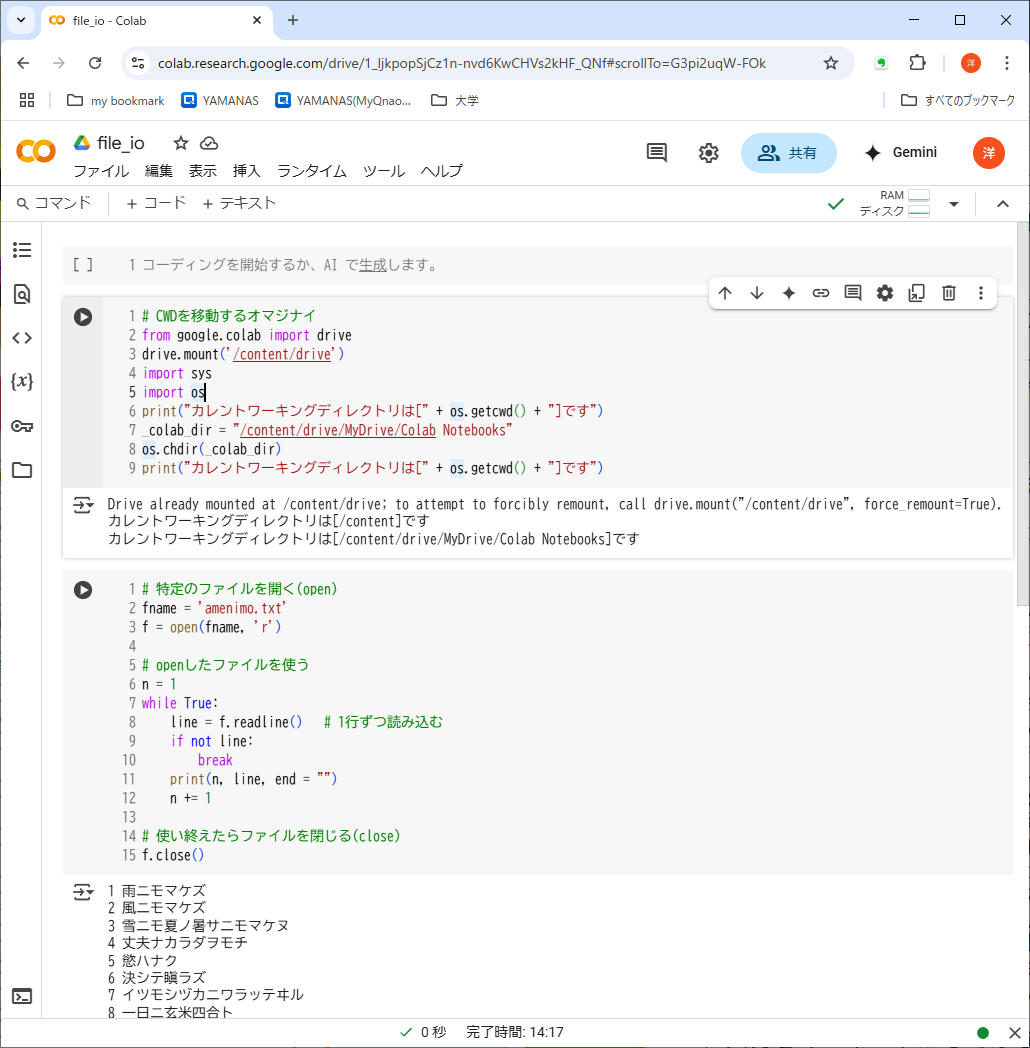
カレントワーキングディレクトリ(CWD)
ここで、Colabでファイル入出力を行う場合の注意点をて説明しなければならない。
プログラムの実行時には、それが「どのディレクトリで実行されているか」という概念が存在し、それをカレントワーキングディレクトリ(CWD)という。入出力ファイルのファイル名(正しくはファイルパス)を指定するときには、CWDが起点となる。なので、ファイル入出力を伴うプログラムを書く場合は、CWDがどこにあるのかを意識し、必要に応じてそれを移動しなければならない。
そして、多くのプログラマがつまづくところだが、CWDはノートブックがあるディレクトリとは異なる。
この授業の場合、各自のサンプルプログラムは/content/drive/MyDrive/Colab Notebooksに置いてあるはずだが、プログラム実行時のCWDはデフォルトで/contentである。なので、open()関数の引数としてファイル名「amenimo.txt」を渡すと「file not found」エラーが返ってきて首を傾げることになる。
リスト6-2の最初のコードセルは、この現象を回避するオマジナイである。今後頻繁に使うものなので、いつものpng画像形式だけでなく、テキスト形式でも置いておくので、必要に応じてコピペしてほしい※2。このオマジナイにはGoogleドライブのマウントが含まれている。また、CWDの移動元と移動先確認のために含めたprint()関数は省いてもよい。
# CWDを移動するオマジナイ
from google.colab import drive
drive.mount('/content/drive') # Googleドライブにプログラムからマウント
import sys
import os
print("カレントワーキングディレクトリは[" + os.getcwd() + "]です")
_colab_dir = "/content/drive/MyDrive/Colab Notebooks"
os.chdir(_colab_dir) # CWDを移動
print("カレントワーキングディレクトリは[" + os.getcwd() + "]です")
2 第9回の授業で、新しい関数の定義を学んだら、こんな決まり文句は関数として定義してしまうと便利だ。
オマジナイ部分に続くコードセルが「行番号をつける」プログラムの本体である。
まず、目的のファイルをopenし、ファイルオブジェクト(f)※3を得る。ファイル「amenimo.txt」はあらかじめ授業フォルダからダウンロードして、Googleドライブにアップロードしておくこと。、より実用的に使うなら、固定したファイル名ではなく、input()関数でユーザに入力してもらえばよい。このファイルは読み込みモード('r')でオープンされている。
# 特定のファイルを開く(open)
fname = 'amenimo.txt'
f = open(fname, 'r')
# openしたファイルを使う
n = 1
while True:
line = f.readline() # 1行ずつ読み込む
if not line:
break
print(n, line, end = "")
n += 1
# 使い終えたらファイルを閉じる(close)
f.close()
3 ファイルオブジェクトは、他言語の「ファイルハンドル」に相当する、プログラム中でファイルを表すデータ構造である。for line in f:のように、行のリストと見なして繰り返し処理の対象にもできる。その知識(とその他の先進機能)を使えば、このwhileループは、リスト6-3: file_io2.ipynbに示す、極めて簡潔な形に書き直せる。リスト6-2であえて古風なwhile構文を使ったのは、それだとファイルオブジェクトの使い方が見えにくいからである。
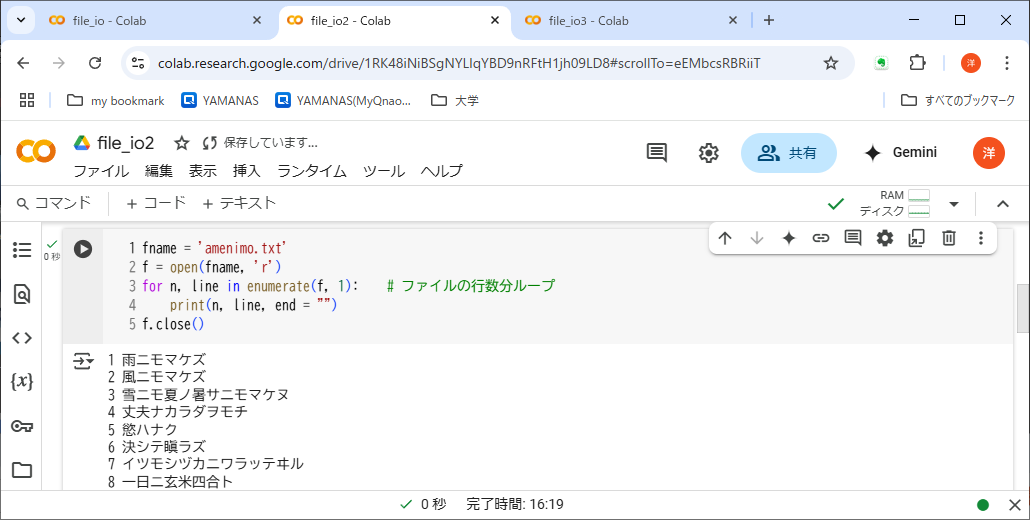
Pythonではファイルオブジェクトもリストのように扱える。つまりfor line in f:とすれば、ファイル中の各行を変数lineに代入できるのだ。ファイルを行のリストと見なしたことになる。enumerate()関数は、リストのインデックスと要素を同時に取得する関数である(第2引数の1は初期値)。
各構文や関数の定義を、教科書で確認しよう。それを面倒がらずにやるかどうかで、プログラミング上達の明暗は別れる。
ファイルのopenモード
ファイルをopenする際には、利用目的に応じて以下のモードを指定できる。
- r
- 読み込みモード。ファイルがなければエラーが発生する
- w
- 書き込みモード。ファイルがなければ新規作成される
- a
- 追加書き込み(append)モード。ファイルがなければ新規作成される
- r+
- 読み書き両用モード。ファイルがなければエラーが発生する
- b
- バイナリモードでopenする。以上の各モードに付加する形式で指定。例:'wb', 'r+b'
たとえば、リスト6-3のプログラム中で、出力用にもう1つファイルを開き、行番号付きの行を書き込むのなら、以下の行を追加すればよい。
fout = open("fout.txt", 'w') # 書き込みモードで開く
str = f'{n} {line}' # 出力文字列を作成
fout.write(str) # foutに書き込み
fout.close() # ファイルを閉じる
ファイル入出力に伴うエラー処理
ファイル入出力では、エラーが発生する場合がある。Pythonにはエラー処理専用のtry~except構文が備わっている。エラー処理は極めて奥深いテーマであり、発生するエラーの種類も千差万別なので、授業ではすべてを扱えない。ここでは、ファイル入出力時に発生する(かもしれない)エラーの処理について解説する。
エラー処理のメカニズムは、try~exceptで囲まれたコードブロック(例によってインデントで示されている)の中で「例外」が発生したとき、その検知をPython処理系に任せるのではなく、プログラムが自分でキャッチして対応することである。
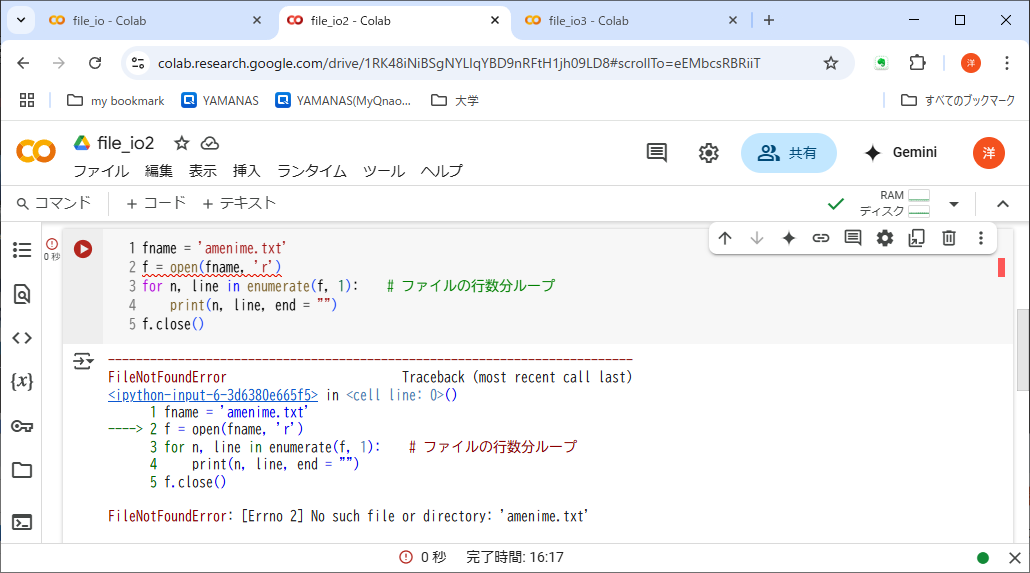
たとえばリスト6-3のプログラムで、ファイル名をタイプミスしたため、開けなかったとする。このとき、open()関数ではIOError例外が発生する。この例外がPython処理系によって検知されると、リスト6-4に示すように、コードセルの出力アクションにエラーメッセージが表示され、プログラムの実行は異常終了してしまう。メッセージ中にある「FileNotFoundError」は、「IOError」の一種(子クラス)。
エラー処理は、例外発生時にも実行を継続するためのものである。たとえば上記のIOError例外を処理するには、リスト6-5のようにプログラムを変更する。
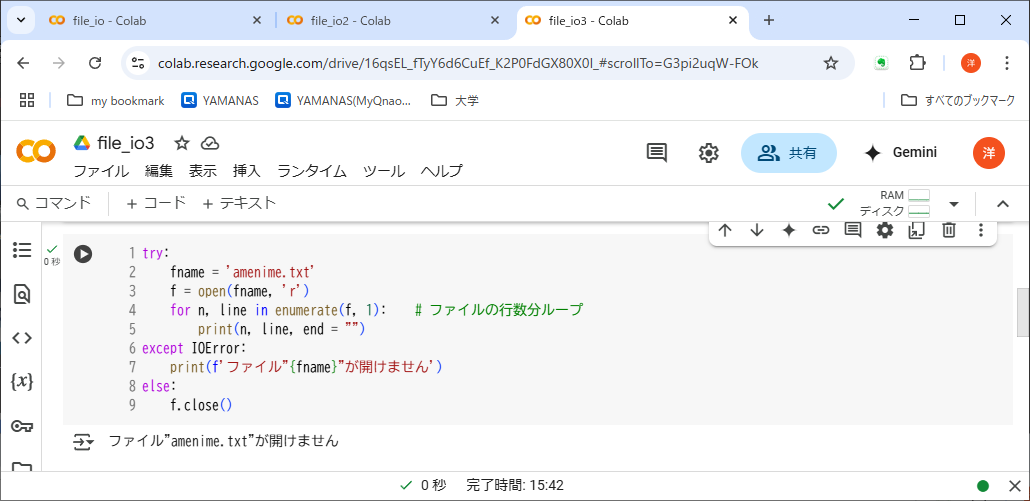
リスト6-5では最終行まで実行されたのでプログラムは終了しているが、Python処理系によって強制的に異常終了させられたのではない。open()関数でIOError例外が発生したとき、実行点はexceptブロック(ここではprint()関数)に移動し、正常に続行されるのだ。なので、この後にユーザにファイル名を入力しなおしてもらうといったコードを追加すれば、プログラムは正常系の流れに復帰できる。
終わりから2行目のelseはtry~except構文の一部である。つまり、「例外が発生しなかったら」の意味だ。
実は、Pythonのelseは、
- ifを受けるelse
- ifの条件式が成立しなかったら~
- while, forを受けるelse
- ループがbreakしなかったら~
- try~exceptを受けるelse
- 例外が発生しなかったら~