step10 集合とディクショナリ
step04で学んだリストやタプルは、複数の値を1つの名前で格納できる便利なデータ構造であり、これがなくては書けないプログラムも多い。そもそも、プログラムは多数のデータを次々に処理するためのものだから、これらの必要性は自明である。
だが、複数の値を格納できるデータ構造はリストやタプルだけではない。pythonにはさらに
- 集合
- ディクショナリ(辞書)
集合
集合の性質
集合(set)は数学の「集合」概念に近いデータ構造である。リストが複数の値を順序をもつ列として格納し、符号なし整数のインデックスにより値にアクセスするのにたいし、集合は複数の値を順序も重複もない集まりとして格納する。順序がないから、当然、インデックスによるアクセスもできない。値(要素)の追加と削除、集合に含まれるかの判定のような基本的な集合操作と、数学的な集合演算、すなわち和、交差、差などがあるだけだ。
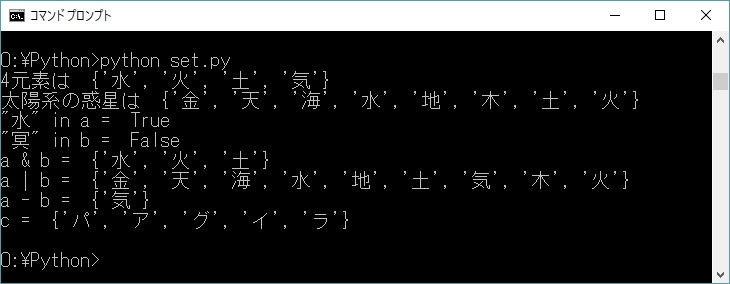
リスト10-1のプログラムで、集合の性質を確かめよう。
これを実行すると、図10-1のような結果になる。集合に格納(追加)するときに、重複する要素は取り除かれることに注意。
uniqコマンドを作る
「集合が数学の『集合』に近い性質をもつのはわかったけれど、これって何の役に立つんですかぁ?」
という声が聞こえてきそうだ。実は講師自身も、教材になるような集合の利用法をなかなか思いつけなかった。でもはたと気づいたのは、重複がないという数学的性質に素直に即した使い方をすればよい、ということだ。
step06で、パイプ機能の解説のために、入力ファイルの行の重複を取り除くuniqコマンドを紹介した。uniqは仕様上、隣り合った行の重複しか取り除いてくれないので、ファイル全体の異なり行を求めるには、
sort < love.txt | uniq
だがそもそも、行の順序など関係なく重複行を取り除いてくれないのはケチくさい。そこで、リスト10-2の【 空欄 】を埋め、ファイルの異なり行のみを出力するコマンドuniq.pyを作ってほしい。
python uniq.py < love.txt
hug
kiss
embrass
marry
ディクショナリ
集合は、ある値が含まれているかの判定には便利だが、インデックスによるアクセスができないため、リストより使用場面は限られる。
それに対し、リスト以上の有用性をもつデータ型がディクショナリ(辞書)である。その名の通り文字列をインデックスとして個々の要素にアクセスできるデータ構造だ。他の言語(たとえばPerlなど)ではハッシュや連想配列という名前で実装されている。
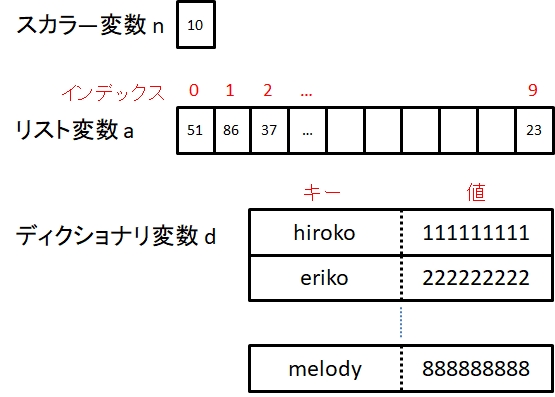
従来のデータ構造であるスカラーやリストと、ディクショナリの違いを、図10-2に示す。
「キー:値」ペア
ディクショナリの要素にアクセスするための文字列を、リストのインデックス(これは整数)と区別するため、キーという。キーによってアクセスされる要素が値である。
値は重複してもよいが、キーは重複できない。つまりディクショナリは、「キー:値」の組(key-value pair)を複数格納した集合だといえる。
ディクショナリがリストより有用な場面は多い。たとえば人名に対して、電話番号や住所などの個人情報を格納し検索する、アドレス帳のようなアプリケーションを考えよう。リストでこれを実現するには、
- 人名を格納したリストを先頭から探し、インデックスを突き止める。なければその人の個人情報は格納されていない。
- そのインデックスで、別のリストにアクセスし、個人情報を取り出す。
ただし、ディクショナリの側から見ると、キーとしてどんな文字列が入ってくるかは事前に予測できないので、「キー:値」の組をメモリ上にバランスよく配置するのはかなり高度なアルゴリズムを必要とする※1。私たちユーザはそれをpython処理系に任せて、効果のみを享受できるのだ。
1 pythonはこの目的を達成するのにB木という、データベース管理システムでも使われるデータ構造を利用している。
近年、深層学習などの応用に向けてビッグデータの活用が盛んになってきた。ビッグデータはデータベースに格納するが、従来の主流であるリレーショナル・データベース(RDB)では、テーブル(表)の演算に計算コストがかかりすぎて、データ量(key-value pairの数)の規模拡大に対応できなくなってきた。そこで、RDBに代わり、key-balue pairを大量に格納し、高速にアクセスできるKVS(key value store)という新しいデータベース管理システムが利用されるようになった。KVSはいわばDB化されたディクショナリであり、当然ディクショナリとの親和性も高い。
pythonにも、ディクショナリのデータを永続的記憶(アプリが終了しても残る)する手段がいくつか存在する。step11で作成する「電話帳データベース」でも、データの永続化は中心課題だ。このように、ディクショナリは本格的なDB利用アプリへの架け橋であるから、しっかり理解しておこう。
人名から電話番号を返す
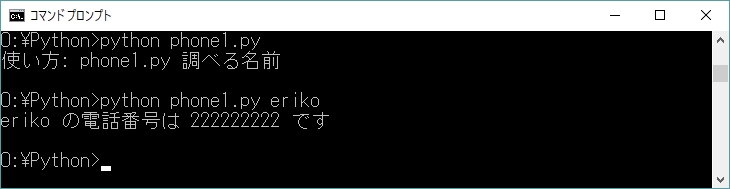
ディクショナリを使って簡単な電話帳を作ろう。リスト10-3にプログラムを示す。
実行例を図10-3に示す。コマンドライン引数で指定した名前から、電話番号を検索している。コマンドライン引数が足りないときには、エラーメッセージとしてこのような使い方(usage)を表示するのが、CUIプログラミングの作法だ。
人名を「キー」、電話番号を「値」とするディクショナリが、プログラムの冒頭で定義されている。ディクショナリの初期化構文を書くのは結構面倒で、せっかく卒業したハードコーディング(処理対象の値をプログラムに埋め込むこと)に逆戻りした思いがする。これを解決するには、ディクショナリの内容をファイルに保存したり、読み出せなくてはならない。次回の課題レポートで、各自取り組んでほしい。
演習:「電話番号登録機能(?)」の追加
上記のプログラムに、新たな「名前:電話番号」ペアを登録する機能を追加してみよ。
売り上げ計算プログラム
ディクショナリを使って、もう少し複雑なプログラムを書いてみよう。果物屋の売り上げを計算するプログラムである。
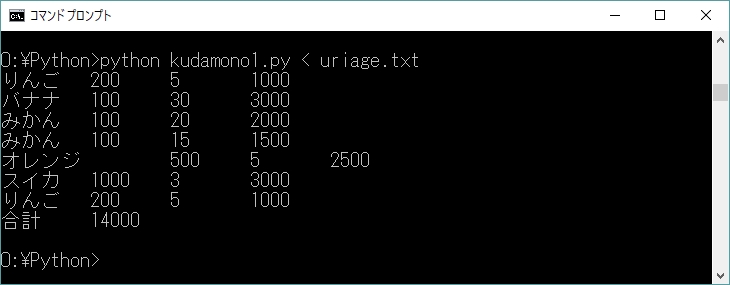
果物の単価表は、プログラムの冒頭で定義されている。果物の売り上げ個数を記したテキストファイル
プログラムをリスト10-4に、実行画面を図10-4にそれぞれ示す。
演習:「単価表」のファイル化(外部化)
単価表をテキストファイル
から読み込むように、リスト10-4のプログラムを改造せよ。