step08 書式指定と正規表現
pythonは何でも書ける汎用性の高い言語だが、とりわけテキスト(文字情報)処理を得意とする。この点ではPerlやRubyといった先行言語の流れを汲む、正統な後継言語だといえる。
このstepでは、テキスト処理のための強力な機能である書式指定と正規表現を学ぶ。
書式指定による整形出力
書式指定とは、標準出力やファイルに書き込むテキストの形式を細かく制御する構文である。これまでのサンプルプログラムでは、値を出力する変数や文字列を、print()関数の引数として並べて指定したり、
print('Howdy,', name, '!')
print('鈴木さんに' + str(suzuki) + '円返す')
そこで、多くのプログラミング言語と同様に、pythonでは、書式を表す文字列に、表示される要素(変数など)を埋め込むことで、出力するテキストの形式を整える機能を持っている。これを書式指定つき出力という。
文字列の書式指定には新旧2種類の方式がある。Python2からPython3へ、互換性のないバージョンアップを行った歴史的理由によるのだが、これから学ぶみなさんは、ここで解説する新方式だけを学べばよい。
これには、記号{ }とformat()メソッドを用いる。メソッドとは、【応用編】で扱う「クラス」に付属する関数だが、ここでは文字列クラスに備わっている機能と考えればよい。
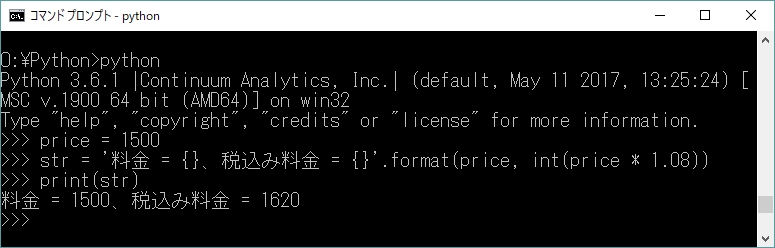
実際に整形出力を行うには、書式を指定する文字列のメソッドformat()を呼び出し、その引数として埋め込む変数や値を指定する。図8-1に例を挙げる。
いちいちプログラムファイルを作るのも面倒なので、ここではpythonプロンプト※1で実験している。
1 プログラムを1行ずつ処理系に与え、対話形式で結果を表示させる実行方式。引数なしにpythonと入力するとこのモードに入れる。条件分岐や繰り返しを含む長いプログラムは書けないが、簡単な構文の確認などには便利である。対話モードを終了するにはquit()を入力する。
ここで、書式文字列は'料金 = { }、税込み料金 = { }'である。文字列クラスのformat()メソッドに与えられた2つの引数、priceとprice * 1.08が、書式文字列中の{ }という「穴」に埋め込まれることで、整形が行われ、結果が変数strに代入される。
また、{ }内でformatメソッド中の引数の位置を指定できる。指定はリストのインデックスと同様、0から始まる整数で行う。図8-2に例を挙げる。
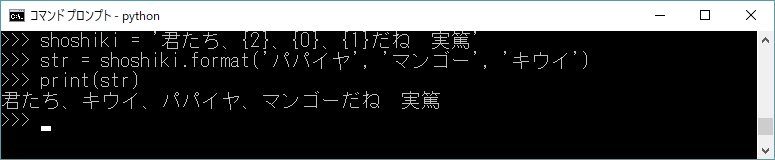
また、ここでは、書式指定の{ }に埋め込まれる引数をデフォルトの書式で、つまり処理系任せで表示していた。だが、位置指定に続けて(または省略されていても)「:」を書き、さらに値毎の書式指定を置くことで、データ型や形式
- 整数の桁数
- 浮動小数点数の小数点下の桁数
- 2進数や16進数・8進数
- 表示幅
- 揃え
- 「0」などでの文字埋め
さらに、formatメソッドの引数にリストやディクショナリを渡し、書式指定中でその要素にアクセスしたりもできる。
{ }内の記法は書式指定ミニ言語という独立した文法に則っり、これはかなりのボリュームがあるため、この単元では到底説明しきれない。詳細はpython言語リファレンスの「6.1.3. 書式指定文字列の文法」を参考にしてほしい。
f文字列
f文字列はpython3.6から導入された最新機能で、正式名を「フォーマット済み文字列リテラル」という。これまでに述べた書式指定をいっそう簡単な構文でできるようにしたものだ。
これまでに書いたいくつかの例をf文字列を用いて書き直すと、以下のようになる。
print(f'Howdy, {name}!')
print(f'鈴木さんに{suzuki}円返す')
print(f'料金 = {price}、税込料金 = {int(price * 1.08)}')
{}の中には、埋め込む変数を直接入れる。最後の例のように式を入れることもできる。
文字列に対するformat()メソッドが不要な分、短く書け、処理内容も分かりやすい利点がある。また、format()メソッドで可能な細かい書式制御も指定できる。例えば、2番目の例において、小数点以下の桁数を制限したい場合には、以下のように書けばよい(format()メソッドでも同じ)。
print(f'鈴木さんに{suzuki:.2f}円返す')
正規表現によるテキスト検索
正規表現※2とは、特定の条件にマッチする文字列を検索したり、見つけ出した文字列を別の文字列に置換するための手段である。検索や置換の条件はパターンと呼ばれる定型文字列で表現される。正規表現のパターンには、特有の文法があるが、やや複雑なため、慣れるにはちょっとした練習が必要だが、テキスト処理には大変便利で強力な手段なので、ぜひ習得するべきだ。
正規表現はpythonの専有物ではない、PERLでは言語の文法自体に正規表現を扱う機能が統合されているし、他の多くの言語でもライブラリとして利用できる。「秀丸」などのテキストエディタでも、検索や置換機能で正規表現を利用できる。
つまり、正規表現は、特定の言語やアプリから独立した、テキスト処理のための汎用技術なのである。
2 英語でregular expression。RE、regex、regex pattern、regexpなどさまざまに略記される。
検索とは何か
そもそも検索とは何だろうか。私たちは図書館で蔵書を検索したり、Webで情報を探したりするが、検索の定義を正確に説明できる人は少ないだろう。
図8-3に検索のモデルを示す。検索の対象となるものは、何らかの集合である。この集合を全体集合Sとする。要素はどんなものでもよいが、正規表現の場合には文字列であり、1つのファイルのすべての行をイメージしてもよい。
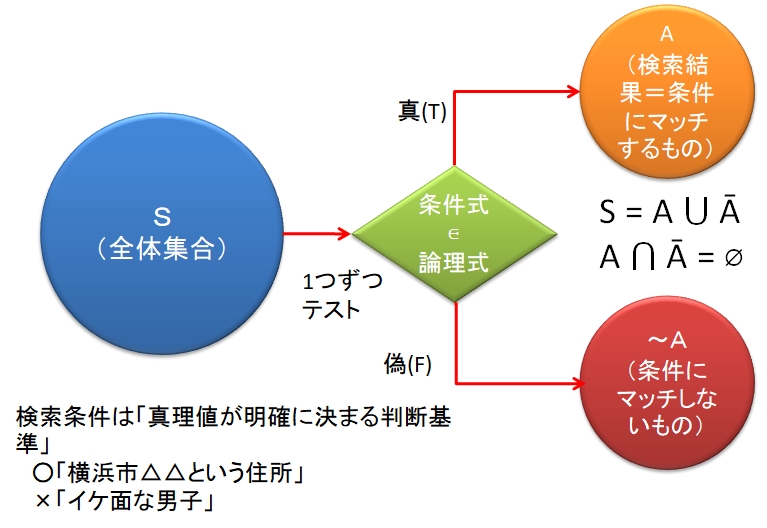
検索とは、
全体集合Sに属するすべての要素を、検索条件によってチェックし、あてはまる(条件にマッチする)要素の集合Aを取り出すこと
全体集合Sを2つの部分集合Aと~Aに分ける操作
ここで検索条件は、Sの要素を含む条件式によって表現される。条件式は論理式の一種であり、与えられた要素に対して真(True)または偽(False)のどちらかの値(真偽値)を取る※3。
3 pythonなどのプログラミング言語では、真を「0以外の数」、偽を「0」と対応づける。また、条件式は真偽どちらかの値を必ずとるから、あいまいな条件ではいけない。
ちなみに、あいまい検索というあいまいな言葉があるが、これは「記憶があいまいな時に用いる検索」とでも解釈すべきで、条件自体があいまいでいいわけがない。部分一致検索という正確な名前を使おう。
正規表現パターン
正規表現は十分に強力で、全体集合Sを任意のAと~Aに分割する能力を持っている。つまりすべての異なる検索を表現できる。しかし、検索条件は、たった1行の定型文字列(正規表現パターン)で表わされるので、複雑な検索を実行するには、それだけ複雑なパターンを書く必要がある。自然、求める検索に対応する正規表現を考えることは、パズルを解くのに似てくる。
正規表現の実習をするにあたって、ちょっと準備が必要だ。検索対象の、つまり全体集合Sにあたるテキストファイルを用意しなければならないからである。以下にリンクの一覧を示すので、それぞれのファイル名を右クリックし、「対象をファイルに保存」するとテキストファイルをダウンロードできる(love.txtはstep10 集合とディクショナリで用いるので、ここでついでにダウンロードしておこう)。
- あいさつ
- greetings.txt
- SPEED
- speed.txt
- 人名
- people.txt
- 愛情表現
- love.txt
pythonでは、正規表現を利用するために、パッケージreが用意されている※4。
正規表現パターンは'Good'である。単なる文字列だが、これもパターンの基本的な形態であり、図8-3における「検索条件」に当たる。
引用符の直前の文字「r」は、raw文字列の指定で、文字列に含まれる(かもしれない)特殊文字の働きを抑止する。パターン'Good'は特殊文字を含まないので、この場合に限っては不要なのだが、一般に正規表現パターンは後述のような各種特殊文字をふんだんに含むので、r指定をする習慣をつけたい。
条件判定を実行するのが、関数re.search(pattern, line):である。入力テキスト中の各行を正規表現パターンと比較して、マッチ(適合)すれば真を返す。
このプログラムをテストするには、コマンドラインで、標準入力にファイルgreetings.txtをリダイレクトすればよい。
4 Perlでは、プログラミング言語の中で直接、正規表現をサポートする。このような言語は珍しいが、テキスト処理に強いと言われる所以でもある。だが、pythonを学んだ皆さんが、Perlに戻る必要はほとんどない。
python findgood.py < greetings.txt
if line.count('Good'):
正規表現の簡単なまとめ
正規表現パターンの詳細について、ここですべてを説明することは、とてもできない。正規表現という技術はそれほど大規模で奥が深い。下の5つの表にまとめた事柄以外は、以下のドキュメントを参考にしてほしい※5。
- 教科書の「7.1.3.6 パターンの特殊文字(201ページ)」
- 同じく「7.1.3.7 メタ文字(203ページ)」
- python言語リファレンスの「正規表現 HOWTO」
5 αからΩまで知りたい人には、「決定版」とも言うべき有名な本『詳説 正規表現 第3版』 Jeffrey E.F. Friedl オライリー・ジャパンもあるが、別に奥義を極めなければプログラムが書けないわけじゃない。
多少難解だろうと、1行の正規表現パターンをひねり出すのと、if文の山を築くのと、どちらがいいですかというだけの話だ。
演習:パターンを使ったさまざまな検索
前述のプログラムfindgood.pyを少し修正して、リスト8-2のfindpattern.pyを作成しよう。
そして、パターンを入れ替えながら、つぎのような検索をしてみよう。対象はさきほどダウンロードしたpeople.txtである。
- 苗字がJacksonの人
- Jで始まる人。グループ名などは除く
- 1語の名前
- 3語の名前
正規表現によるテキスト置換
正規表現は、文字列を検索するだけでなく、検索で発見された部分を置換するのにも使える。ただし、置換用のパターンは、検索用のパターンと一部異なる。それは、パターンの一部にマッチした入力文字列の一部を記憶しておき、置換文字列の一部として指定しなければならないからである。
その目的のために、( )と、\1,\2などの特殊文字を用いる(前掲の表「置換文字列中で使える表記」を参照)。
リスト8-3のプログラムは、英語表記の名前と姓を逆転して出力する。ファイルspeed.txtで動作を確認してみよう。
実際に置換を行うのはメソッドre.subである。第1引数のパターン中で、( )内にマッチした文字列が、先頭から順番に記憶され、第2引数の文字列中で\1, \2 ...の位置に展開されることで、具体的な置換動作が実行される。
( )と番号は、出現順に対応づけられる。この例では、\1に名前が、\2に苗字が対応する。