第3回目
【解説1】 構造体と複素数
今回より,複素数を扱います.今後の課題の基礎となる部分ですのでしっかりと理解しておいてください.
複素数については数学の授業で扱ったと思いますので思い出してみて下さい.なお,検索すれば解説の
ページは簡単に見付かると思います.複素数とは,
z = re + j im
で示されるものです.プログラム中では,z = x + j yとします.
虚部に関してはiと示す場合もあれば,jと示す場合もあります.
imageの頭文字で i となりますが他の変数と紛らわしくなる場合もあり,制御などでは
j と表記します.
ここでも j とします.
さて,複素数の概念そのものが計算機にあるわけではありません.
四則演算であれば,メモリ内の数値を直接操作することができるのですが,複素数の場合は異なります.
複素数zの場合,re と im というパラメータを持った関数として扱う必要があります.
現在のC/C++コンパイラでは複素数に関するヘッダファイルは用意されており,簡単に使うことができます.
しかし,マイコン用のコンパイラなど小規模な開発環境だと,必ずしもあるかどうか分かりませんし,フリーの
コンパイラでもサポートされているかどうかは分かりません.
複素数が利用できると言うことは信号処理を行う上で有効ですので自作で使えるようにしておくことに越した
ことはありません.
それでは,以下の複素数の意味を思い出してみて下さい.
| 複素数の演算について [和] 実部,虚部それぞれの和 [差] 実部,虚部それぞれの差 [積] z1 z2 = x1 x2 - y1 y2 + j (x1 y2 + x2 y1) [商] z1 / z2 = (x1 x2 + y1 y2) / (x2 x2 + y2 y2) + j (x2 y1 - x1 y2) / (x2 x2 + y2 y2) [絶対値] |z| = x x + y y [偏角] θ = atan (y/x) [共役複素数] 虚部の符号が変わる [指数関数] 来週の授業中に説明します. [べき乗] 来週の授業中に説明します. [n乗根] 来週の授業中に説明します. |
いろいろと複雑なものになっていることがお分かりいただけたと思います.
さて,複素数を扱う上で,構造体を使えば表現することはできます.例えば以下のように,
| typdef struct COMPLEX_ { double re; double im; } Complex; |
しかしながら,これや上記のような関数を毎回用いるばあい,その関数を毎回演算のために記述するのは
楽ではありません.
しかも,
毎回記述することは間違いのもとでもある
ので,できれば一度書いたらいつでも同じように使えるものを作ってしまった方が良いかと思います.
そこで,情報処理・演習1で用いた分割コンパイルの手法を用います.
http://www.isc.meiji.ac.jp/~re00104/ch13.html
何をするのか整理してみましょう.
この目的を達成するには,
を用意します.
本日の課題は,
1)複素数の各関数作成
2)各関数を利用するための別ファイルのソースとヘッダの作成
3)メインとなるソースにて複素数関数を呼び出して実行
という中身です.
さて,分割コンパイルに関してはちょっと難しかったかと思います.
やっていることを理解するために,以下のものをご覧ください.
| ごく簡単なMakefile |
|---|
|
最終的にはkadai3_1.exeという実行ファイルを作りますが,そのためには
上記のコマンドをひとまとめにしたファイルMakefileを作成します.
なお,拡張子はありませんので御留意下さい.
もう少し詳しく知りたい方は,分割コンパイルをご覧ください.
【解説2】 動的配列
プログラムにおける静的と動的と言われても想像できる人は少ないと思います.
なお,これまでに扱った変数,1次元配列,2次元配列はメモリ内に[静的]に確保されていますが,実は,
作成したプログラムが実行された時,これらのためにメモリのある部分が固定されてしまう問題があるの
です.
充分なメモリ容量とメモリアクセス速度がある場合には別段問題にはなりません,と言いたいところですが,
プログラムを用いて装置を動作させる場合,そうはいえない面があります.
さて,さまざまな機器のメインメモリを考えてみましょう.PCだけでなくスマートフォンも大きなメインメモリを
持つようになっている昨今,プログラムの工夫によってメモリの節約とかあまり言われなくなっています.
むしろ,今や巨大なメモリ実装が誇示される感すらあるくらいかも知れません.
大きくなり続けるPCのメインメモリ
PCの歴史を振り返ってみます.皆さんにとっては生まれた頃からの変化と言うわけです.身近に使われて
いるWindowsとMacについて追っていきたいと思います.
Windows3.1 / System7の時代
| メーカ | 型番 | CPU | クロック | メインメモリ | |
| 1993年 | NEC | PC-9821As | i486 | 33MHz | 640kB+14MB |
| 1994年 | Apple | Color Classic II | 68030 | 33MHz | 10MB |
| 1994年 | IBM等 | PC/AT | i486 | 66MHz | 32MB |
Windows95〜98 NT4.0 / OS8〜9の時代
| メーカ | 型番 | CPU | クロック | メインメモリ | |
| 1997年 | NEC | PC-9821Ra266 | PentiumII | 266MHz | 256MB |
| 1999年 | Apple | Power Macintosh G3 | PowerPC G3 | 400MHz | 512MB |
| 1998年 | 多数 | PC/AT | PentiumII | 450MHz | 256MB |
Windows2000 Xp / Mac OS Xの時代
| 分類 | CPU | クロック | メインメモリ | |
| 2004年 | Win | PentiumIV | 2.8GHz | 2GB |
| 2005年 | Mac | Power Mac G5 | Quad 2.5GHz | 8GB |
Windows7 / MacOS 10.7
| 分類 | CPU | クロック | メインメモリ | |
| 2010年 | Win | Core i7 Extreme | 6Core 3.5GHz | 32GB |
| 2010年 | Mac | Intel Xeon | QuadCore 2.8GHz | 32GB |
Windows8.1 / Mac OS 10.10
| CPU | クロック | メインメモリ | ||
| 2014年 | Win | Core i7 Extreme | 8Core 3.0GHz | 64GB |
| 2013年 | Mac | Intel Xeon E5 | 6Core 3.5GHz | 64GB |
組み込みマイコンの事情
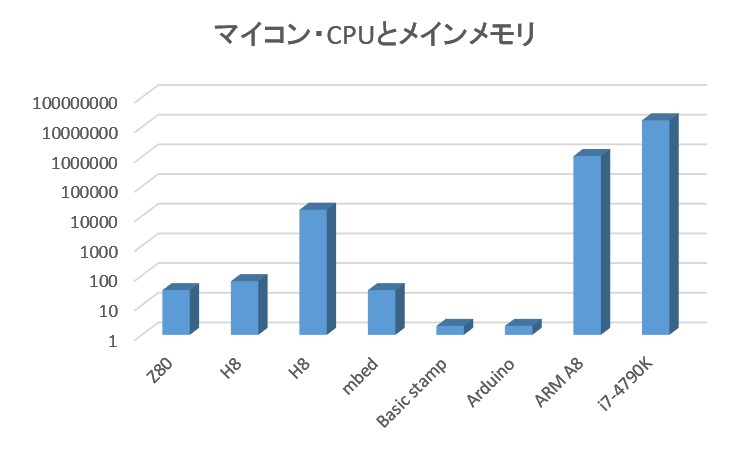
以下のグラフを見てください.単位はkBです.
縦軸は対数で圧縮しています.右二つのグラフはスマートフォンのCPUであるARMとPCのCPUであるIntel
Core i7のもので1GB以上の規模となっています.一方家電製品などを制御するマイコンと呼ばれるものの
メモリは2〜32kBという規模であり,こうしたマイコンの元祖が市場に出た40年くらい前の水準と特に変わり
ません.
ということは,ソフトウェア開発のみで完結するのであればよいのですが,組み込み機器などの場合,プロ
グラムの工夫やメモリなどハードウェアの制限を意識した開発の必要性は今もなおあると考えてよいのです.
以上の背景から,大きな計算負荷,闇雲に消費するメモリ容量を避けたプログラム開発葉いずれにしても
必要な技術であることは間違いありません.
プログラムにおける静的と動的
小さなメモリをうまく利用するにはその使われ方を考える必要があります.プログラムやデータが小さければ
よいのですが,それと同時に有効に使われることが必要となります.
そのためにはどうしたらいいのでしょうか?
必要なときに必要な分だけメモリを利用する,というのがひとつの答えとなるのです.
皆さんがこれまでの演習で扱ってきた変数や配列は静的であり,宣言してプログラムを実行するとメモリの
所定の領域にずっと配置されるものでした.プログラムが大きくなり,扱うデータが大きくなると,メモリを使い
切ってしまうことになり,実行することができなくなってしまうのです.
逐次実行していくようなプログラムの場合,一時にできることは一つだけですので,必要なときにメモリを確
保し,処理が終わったら次のステップのためにその内容を開放するという利用法で解決できます.このような
方法をメモリの動的確保と呼んでいます.HDDにファイルアクセスするのであれば,ある処理が終わったら,
メインメモリの内容をファイルに書き込み,メモリ内を片付けると言った使い方ができるわけです.
メモリ内でのデータの確保
プログラムがメモリにロード(読み込み)され,さらにそのプログラムが実行されるとき,プログラム内の変数に
よって,メモリ確保(アロケーション)が行われます.
なお,プログラムが格納され,主なデータ処理がなされるメインメモリの構造は以下の概念図で示すことが
できます.
| アドレス | データ |
| 0x00000000 | ・・・・・・・・ |
| 0x00000001 | ・・・・・・・・ |
| 0x00000002 | ・・・・・・・・ |
| ・ | ・・・・・・・・ |
| ・ | ・・・・・・・・ |
| ・ | ・・・・・・・・ |
| ・ | ・・・・・・・・ |
メインメモリとして実装されているだけ,アドレスとデータの組み合わせが延々と続くイメージだと考えてください.
メモリ確保については,大雑把に挙げると以下のようになっています.
| 固定されて利用 | プログラム領域 | |
| 静的領域 | データ領域 | |
| 変動しながら利用 | ヒープ領域 ↓ |
|
| (空白) |
||
| ↑ スタック領域 |
プログラム領域:プログラムがロードされて格納されるところで,メモリアドレスの先頭に配置されることになり,
プログラム実行中は移動しません.
静的領域:グローバル変数やプリプロセッサなどで定義された定数などが配置されており,プログラム領域に
続いて確保されます.プログラムの実行中は移動しません.
ヒープ領域:動的変数などによって利用され,プログラム実行中に確保されたり,開放されたりする部分であり,
領域の大きさは変化します.
未使用領域:プログラム,静的,ピープ領域からもスタック領域からも確保されない領域であり,一定量は存在
していないとプログラムの実行は不可能となります.
スタック領域:CPU内のレジスタ(演算結果,データのやり取りの状態を高速に保持)の内容を仮置きしたり,
OSやコンパイラによって利用される部分であり,メモリの末尾から確保されます.また,関数内で利用される
ローカル変数,引数,戻り値などもおかれる部分であり,プログラムの実行中に確保されたり,開放されたり
します.
ノードについて
プログラムまたはデータがある部位は使用中ノードと呼ばれ,それ以外の未使用の領域は未使用ノードで
あるといえますが,正確にはもう少し細かく考える必要があります.宣言だけされて利用されない変数であったり
闇雲に確保された変数や配列があり,しかも確保と開放が適切でなかったりすると,使用中ノードの中の隙間に
未使用ノードが増えていってしまい,未使用領域が減少し,ついにはスタックオーバーフローを起こして正常に
実行できなくなってしまいます.
連続してメモリが確保できない場合,マイコンのような小さなメモリの装置においては非常に大きな問題となります.
動的なメモリ確保(アロケーション)のメリット
以上のように,闇雲に変数,特に大きな静的配列を設定し,これを繰り返す構造のプログラムを作ってしまうと,
不連続にメモリが確保されて,有効なメモリ領域を圧迫してしまう問題がありますが,動的に変数や配列を確保し
適切に開放するようにすれば守り空間を効率的に隙間なく利用することができ,オーバーフローの問題を回避
することができるようになります.
動的1次元配列
ご存知のとおり,double x[100]の場合,8byteで100個分のデータを格納するものであり,宣言に仕方によって,
静的領域またはスタック領域に確保されます.
これに対し,配列動的に確保する場合の考え方は,
と言うものです.以下の2つのコマンドが対応します.
malloc関数
型 *動的配列名 = (型 *)malloc(配列数*sizeof(型));
として定義できます.具体例を示すと,
double *d_array = (double *)malloc(100*sizeof(double));
のようなものとなります.動的配列名d_arrayとして,ポインタで宣言し,double型の配列データ数100個のメモリを
確保する,と言う意味です.
calloc関数
型 *動的配列名 = (型 *)calloc(配列数, sizeof(型));
として定義できます.具体例を示すと,
double *d_array = (型 *)calloc(100, sizeof(double));
のようなものとなります.動的配列名d_arrayとして,ポインタで宣言し,double型の配列データ数100個のメモリを
確保する,と言う意味で同様ですが,calloc関数の場合,宣言した後,全要素に関してゼロで初期化するように
なっています.
なお,いずれの関数であっても,
free(動的配列名);
具体的には,
free(d_array);
とすれば,領域を解放することができます.
サンプル
| #include <stdio.h> #include <stdlib.h> int main(){ int i; double *d=NULL; d=(double *)calloc(100, sizeof(double)); if(d==NULL){ puts("メモリ不足!"); exit(EXIT_FAILURE); } d[0]=1.23456; d[99]=7.89012 for(i=0; i<5; i++){ printf("d[%03d]=%f\n", i, d[i]); } for(i=95; i<100; i++){ printf("d[%03d]=%f\n", i, *d(i+1)); } free(d); exit(EXIT_SUCCESS); } |
動的配列のためのポインタを宣言 calloc関数 確保した動的配列の中身を確認 実行を中止し,エラーコード 配列の中身を代入 配列の中身を代入 はじめから読むときは配列のように扱える. 途中から読むときはポインタで読み込む. 領域を開放する. 問題なく実行できたコード |
参考 C++
malloc関数の代わりにnew演算子が利用できます.
double *d_array = new double[100];
のようにすればよく,calloc関数のようにゼロで初期化するするには,
memset(d_array, 0, 100U*sizeof(double));
とすればよいのです.なお,引数を見てのとおり,0以外の数値で初期化することも可能となっています.
動的2次元配列
2次元配列を想像するとき,数学の行列を連想するが,メモリにおいては行列の意味はないことを留意
する必要があります.
2×2行列のように見えるs_array[2][2]については,4つのデータが連続して並んでいるだけであることを
思い出してください.
従って,ある行数,列数の場合,
型 *動的配列名 = (型 *)malloc(行数*列数*sizeof(型));
のようにメモリを確保することになります.10行15列の場合であれば,
char *d_array = (char *)malloc(10*15*sizeof(char));
のような宣言をすることになります.なお,1次元とは異なり,calloc関数のような初期化はできません.
従って,全データを初期化するためのコードを入れるなど,工夫が必要となります.
また,静的2次元配列のようにs_array[i][j]と明示できているわけではないので,プログラムには工夫が
必要ですので,以下のサンプルを参考にして下さい.
| #include <stdio.h> #include <stdlib.h> #define A 4 #define B 2 #define M(a, b) m[(a)*(B)+(b)] main(){ int a, b; char *m=(char *)malloc(A*B*sizeof(char)); if(m==NULL){ puts("メモリ不足!"); exit(EXIT_FAILURE); } M(0,0)=0x00; M(0,1)=0x01; M(1,0)=0x10; M(1,1)=0x11; M(2,0)=0x20; M(2,1)=0x21; M(3,0)=0x30; M(3,1)=0x31; for(a=0; a<A; a++){ for(b=0; b<B; b++){ printf("d[%d][%d]=%02X\n", a, b, M(a, b)); printf("\n"); } free(m); exit(EXIT_SUCCESS); } |
行数をプロトタイプ宣言 列数をプロトタイプ宣言 配列の形を定義したプロトタイプ宣言 malloc関数 確保した動的配列の中身を確認 実行を中止し,エラーコード 中身を代入; 中身を代入 中身を代入; 中身を代入 中身を代入; 中身を代入 中身を代入; 中身を代入 行に関するループ 列に関するループ 配列に関してデータ書き出し 改行 領域を開放する. 問題なく実行できたコード |
本日の課題
課題1 複素数の演算について で示した各演算を作成し,関数を扱うための関数complex.cを作成せよ.
関数や変数の意味が分かるよう,コメントは必ず付けておくこと.
今回は和差積商と絶対値,偏角,共役複素数まででよい.(残りは来週)
| #include <stdio.h> #include <math.h> #include "complex.h" Complex ToComplex(double x, double y) /*複素数のパラメータを与える*/ { Complex z; z.re = x; z.im = y; return z; } Complex Cadd(Complex a, Complex b) { Complex z; z.re = a.re + b.re; z.im = a.im + b.im; return z; } Complex Csub(Complex a, Complex b) { 同様 } Complex Cmul(Complex a, Complex b) { 同様 } Complex Cdiv(Complex a, Complex b) { 同様 } double Cabs(Complex a) { double x; x = sqrt(a.re * a.re + a.im * a.im); return x; } double Carg(Complex a) { 同様,関数はatan2を使う } Complex Conj(Complex a) /*共役複素数*/ { 同様 } 以下,次回 Complex Cexp(Complex) Complex Cpow(Complex, double) Complex Csqrt(Complex), void Cdisp(Complex); Complex Cinp(void); |
課題2 以下のヘッダファイルcomplex.hも合わせて作成しておくこと.
来週作成する関数も含まれているので,対応関係を理解しておき,コメント分を付けておく.
| typedef struct COMPLEX_ { double re; double im; } Complex; Complex ToComplex(double, double), Cadd(Complex, Complex), Csub(Complex, Complex), Cmul(Complex, Complex), Cdiv(Complex, Complex), Conj(Complex, Complex), Cexp(Complex, Complex), Cpow(Complex, double), Csqrt(Complex), Cinp(); double Cabs(Complex), Carg(Complex); void Cdisp(Complex); |
課題3 動的な3次元配列を作成せよ.4×3×2の配列とする. ar[4][3][2]に相当すると考えればよい.
各要素はint型とする.上記のサンプル同様に,プログラム中で各要素を任意に代入し,その結果を出力すること.
ヒント
確保すべき領域A*B*C*型
任意の要素の定義((a)*(B)+(b))*(C)+(c)
実行結果例
000 001
010 011
020 021
100 101
110 111
120 121
200 201
210 211
220 221
300 301
310 311
320 321
※今回の課題は,多くのことを含んでいるため,できたところまでで問題ない.
来週も引き続き解説しながら,新しいことを追加するので,もう一度完成版を提出すること.
今回は,bcc32 -c complex.cとタイプすれば,コンパイルだけでき,文法のミスはチェックできる.
余力のある人は以下のようなmain.cを作り関数を呼び出して使ってみて欲しい.
| #include <stdio.h> #include <math.h> #include "complex.h" main() { Complex x, y; int ??? double ??? 呼び出したい関数 printf("re im = %g %g |n"), x.re, x.im; printf("re im = %g %g |n"), y.re, y.im; } |
※情報処理演習1ではC++言語を用いたので拡張子はcppとなる.こちらを用いても良い.