Python言語はインタプリタ言語であるため,ソーティングや数値計算などの基本的な処理アルゴリズムを記述・実行すると,とても遅くなる.C言語で記述した方が圧倒的に高速である.
したがって,Pythonでは自分でアルゴリズムを記述するよりも,すでに用意されている様々なパッケージ・ライブラリを順次組み合わせて,それをスクリプト的に実行するような書き方が一般的である.
基本の手順はC言語と同じく,「開く」「読み書き」「閉じる」.
f = open('sample.txt', 'w') # 引数はCのfopen()と同じ.ファイル名とモード
f.write('Hello World!\nGood Bye!')
f.close()
ファイル名などは,変数を使おう.
fname = 'sample.txt'
f = open(fname, 'w') # 'w' は書き込みモード
data = 'Hello World!\nGood Bye!'
f.write(data)
f.close()
fname = 'sample.txt'
f = open(fname, 'r') # 'r' は読み込みモード
line = f.readline() # (改行コードも含め)1行読み込み
print(line)
f.close()
これだと1行しか読み込まれないので,
fname = 'sample.txt'
f = open(fname, 'r')
for line in f:
print(line) # line は1行分のデータ
f.close()
実行結果
Hello World!
Good Bye!
print で表示すると,改行コードが余分に入るため,1行空行ができる.
この方法では,ファイルからの読み込み処理と,計算処理とを分離できる.
ファイルサイズがそこそこ大きくても効率よく自動的にメモリが確保され,高速に読み込める.
f = open('sample.txt', 'r')
lines = f.readlines()
f.close()
print(lines)
実行結果
['Hello World!\n', 'Good Bye!']
以下は 10万行分の数値の書かれたデータファイル data.csv を読み込んで,平均値を画面に出力する例である.
ファイルには 0∼1 までの乱数が書かれているので,平均値は 0.5 前後になる.
注:data.csvは1.3MB程度あるため,プログラムの実行テストが終わったら削除しておいた方が良い.
#
# ファイル内の数値を読み込んで平均値を計算
#
f = open('data.csv', 'r')
lines = f.readlines()
f.close()
N = len(lines)
print(N, 'lines in file.')
sum=0.0
for i in range(N):
# print(float(lines[i])) # 毎行表示
sum += float(lines[i])
print('average =', sum/N)
ファイル処理は,なんだかんだエラーが発生する.
書き込むファイルが他のアプリでロックされている.
読み込むファイルが存在しない.など.
エラー処理には,「例外処理」を使用する.詳しい説明はここでは省略.
fname = 'non-existing-file.txt' # 存在しないファイル名
try:
f = open(fname, 'r')
lines = f.readlines()
except:
print('読み込めなーい')
else:
print('読み込みました.')
print(lines)
f.close()
finally:
print('おしまい.')
実行結果:
読み込めなーい
おしまい.
ここではこれ以上詳しい説明は行わないが,さらなる詳細な解説は公式ドキュメント内にある「チュートリアル」「言語リファレンス」「ライブラリーリファレンス」を参照するとよい.
また,プログラミングに際しては,これ以外にも多くの重要なトピックがある.
興味がある諸君はインターネットのサイトや書籍などを積極的に調べて学習してみよう.
Pythonはインタプリタ言語であるため,自分でアルゴリズムをゼロから記述しても処理が遅いことが多い.
(逆に,C言語では下手なプログラムを適当に書いても,そこそこ高速に処理できる.)
むしろ,いろいろな既存のパッケージ等をうまく組み合わせて使用するのが吉である.
(Pythonのパッケージの内部処理は,高速化のためにC言語などで書かれている.)
よく使われるパッケージ類などを紹介する外部サイトへのリンクです.
Python本体のインストール方法はこちらを参照.
Macの場合,「アクセサリ」の「ターミナル」から
$ sudo pip3 install matplotlib password: (管理者のパスワードを入力) Collecting matplotlib Downloading matplotlib-3.3.2-cp38-cp38-macosx_10_9_x86_64.whl (8.5 MB) |████████████████████████████████| 8.5 MB 5.3 MB/s
Windowsの場合,「Windowsシステムツール」「コマンドプロンプト」を(管理者として)実行し,
> pip install matplotlib ...省略...
この際,他の関連パッケージもインストールされる場合がある.
以下に簡単なグラフ作成の例を示す.
# matplotlib をインポート
import matplotlib.pyplot as plt
# 適当な配列データ
x = [1, 2, 3, 4, 5]
y = [10, 9, 7, 4, 1]
# グラフを描いて表示
plt.plot(x, y)
plt.show()
表示されたグラフの設定を変えたり,ファイルに保存することもできます.
これでも何となくデータの形はわかりますが,工学文書の作法に則ったグラフにするには,もう少し軸や色の設定がいろいろ必要です.
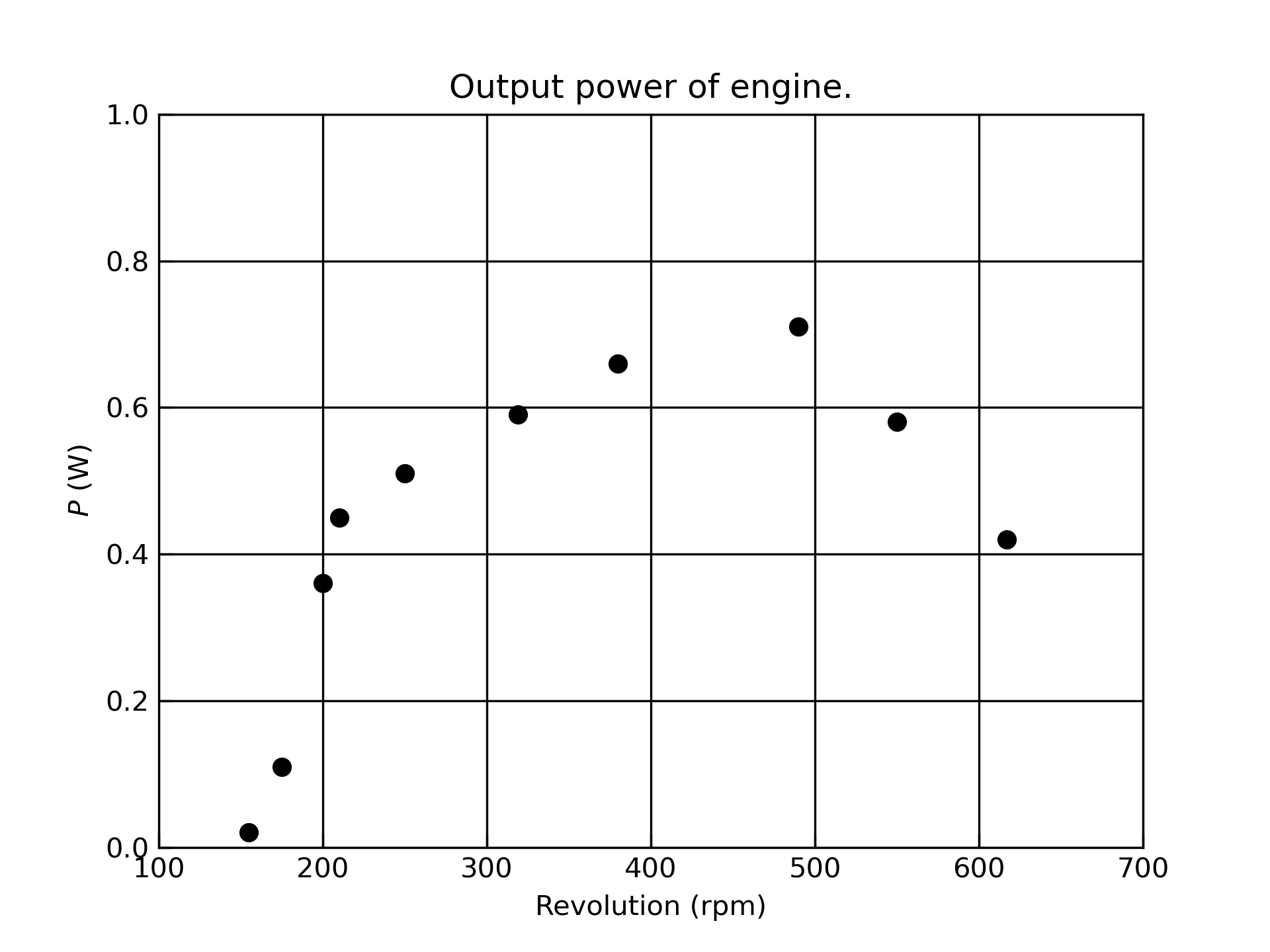
以下のプログラムでは,軸の説明や範囲,プロットの色などを設定したうえで,ファイルに自動保存します.
このソースは,githubに置いてあります.
import matplotlib.pyplot as plt
import numpy as np
# data set, omega and power
RPM = [ 155, 175, 200, 210, 250, 319, 380, 490, 550, 617]
Pout = [ 0.02, 0.11 , 0.36, 0.45, 0.51, 0.59, 0.66, 0.71, 0.58, 0.42 ]
# draw scatter plot
plt.scatter(RPM, Pout, marker='o', color = 'black', label='high')
# configure title, axis label and grid
plt.title('Output power of engine.')
plt.xlabel('Revolution (rpm)')
plt.ylabel('$P$ (W)')
# add axis tick
ax = plt.gca() # get current axis
ax.tick_params(direction = 'in', length = 5)
# set range of axis
plt.xlim(100, 700)
plt.ylim(0, 1.0)
# grid lines
plt.grid(True, color='black')
# save figure to file
plt.savefig('figure1.pdf') # PDF file
plt.savefig('figure1.png', dpi=300) # png image file
# Show image
plt.show()
実行結果.以下のようなグラフが表示されると思います.
同時に,作業フォルダ内にこの画像が figure1.png, figure1.pdf として保存されます.
機械学習のための様々なフレームワークが提案されている.現状,PyTorch と Tensorflow が2大勢力である.