R言語における和の速度比較
川久保圭吾
2016年1月20日
R言語で\(\sum\limits_{k=1}^n \frac{1}{k^2} \ (\to \frac{\pi^2}{6} \ (n \to \infty))\)を計算したいとする.そのときに例えば
forを使う
sumを使う
という2つの方法が考えられる. R言語ではforなどのループは実行時間がかかるというが,実際にどれほど違うのかを調べてみよう.
N <- 7 #n = 10^N までの和をとる
x <- 1/(1:(10^N))^2
time_for <- numeric(N) #forでかかる時間
time_sum <- numeric(N) #sumでかかる時間
for(i in 1:N){
sum_for <- 0 #forによる和
sum_sum <- 0 #sumによる和
time_for[i] <- system.time( #かかる時間を代入
for(j in 1:(10^i)){
sum_for <- sum_for + x[j]
}
)[3]
time_sum[i] <- system.time(sum_sum <- sum(x[1:(10^i)]))[3]
}
print(cbind(time_for, time_sum, time_for/time_sum))## time_for time_sum
## [1,] 0.001000000000203726813197 0.000000000000000000000000
## [2,] 0.000000000000000000000000 0.000000000000000000000000
## [3,] 0.001000000000203726813197 0.000000000000000000000000
## [4,] 0.011999999998806742951274 0.001000000000203726813197
## [5,] 0.126000000000203726813197 0.002000000000407453626394
## [6,] 1.274999999997817212715745 0.018000000000029103830457
## [7,] 13.438000000001920852810144 0.153000000002066371962428
##
## [1,] Inf
## [2,] NaN
## [3,] Inf
## [4,] 11.99999999636202119291
## [5,] 62.99999998726707417518
## [6,] 70.83333333309754209495
## [7,] 87.83006535830347161209plot(log(time_for),
ylim = c(log(min(time_for[time_for != 0], time_sum[time_sum != 0])),
log(max(time_for[time_for != 0], time_sum[time_sum != 0]))),
xlab = "N",
type = "o")
lines(log(time_sum), col = "red", type = "o")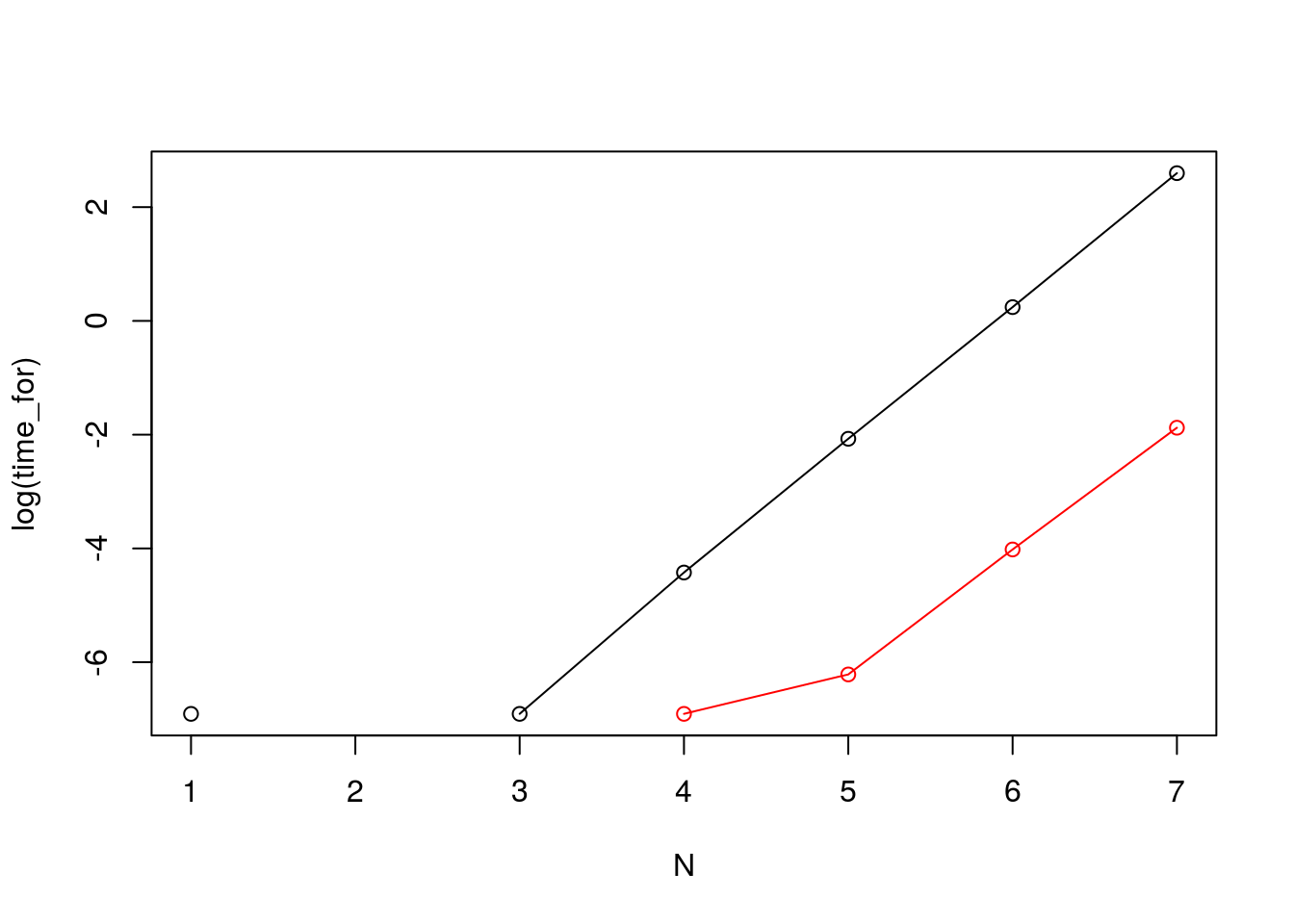
sumはC言語で書かれている(参考:山田亮「遺伝統計学の基礎 Rによる遺伝因子解析・遺伝子機能解析」2010,オーム社,pp 355~356( http://www.statgenet.med.kyoto-u.ac.jp/StatGenet/ryamada_bon/SaikouPDFs/GNMT_CHAPA.pdf 2016年1月19日アクセス)) ので,実行時間が短くなる.
また,このような和を計算する場合に\(k=1\)から和をとると,\(k\)が大きくなるとそれまでの和と次に足す項の絶対値が大きく異なるために情報落ちが大きくなってしまう. そのため\(k=N\)から和をとる.
sum_for_rev <- 0
for(i in (10^N):1){
sum_for_rev <- sum_for_rev + x[i]
}
print(
rbind(
c("sum_for", sum_for),
c("sum_for_rev", sum_for_rev),
c("sum(x)", sum(x))
)
)## [,1] [,2]
## [1,] "sum_for" "1.64493396684732"
## [2,] "sum_for_rev" "1.64493396684823"
## [3,] "sum(x)" "1.64493396684823"逆順に足した方がsum(x)と等しくなっていることがわかる.