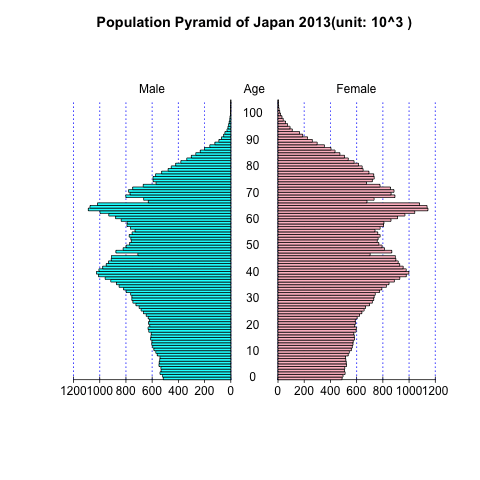
Rで人口ピラミッドを描く
国立社会保障・人口問題研究所の日本の将来推計人口(平成24年1月推計)(2002年1月30日) のデータをつかい、将来の人口ピラミッドの推移をRで描いてみよう。
既に、人口問題研究所では人口ピラミッドの推移を提供している(不気味なアニメーションだ)。 これと同じような人口ピラミッドを描くことが目的だ。
Rパッケージ pyramid を入手する
いささか天下りだが、Rで人口ピラミッドを描くパッケージ(でも、R内ではライブラリという)を使ってしまう(^^;
現在のパッケージの読み込み情況
現在のRに読み込まれているパッケージは、Rの[パッケージとデータ]/[パッケージマネージャ]から一覧されるロード済みがそうである。 RStudioでは[Package]から一覧される[v]とチェックが入ったものがそうである。
パッケージ一覧にあるパッケージをRに読み込むには、以下で述べるように目的のパッケージにチェックを入れる。 そうすると、コンソール画面に選択したパッケージが読み込まれた旨のメッセージが表示される。
新規パッケージの入手
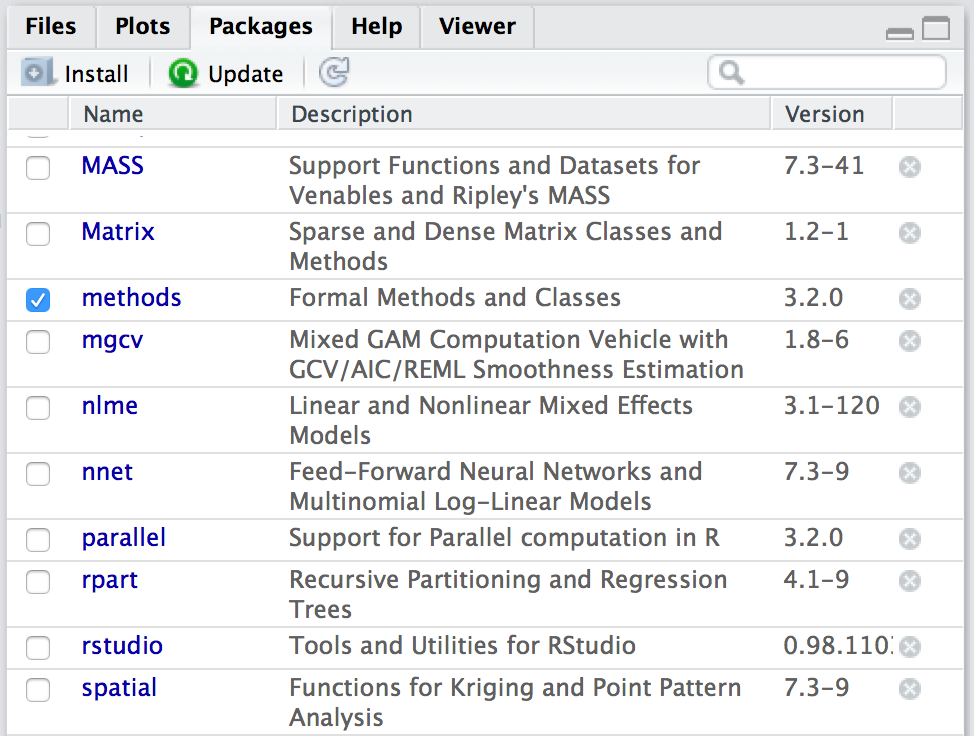
パッケージ一覧にないパッケージはCRAN(he Comprehensive R Archive Network)からインストールしよう。 Rの[パッケージとデータ]/[パッケージインストーラ]から、pyramidを入力して「一覧を取得」。 2012年5月現在で、リポジトリにあるのは pyramid 1.2 であることがわかる。 これを選択し、「選択をインストール」で、pyramid がインストールされる。
RStudioでは、[Package/Install]から目的のパッケージ名 pyramid を正しく入力して[Install]ボタンを押す。 すると、コンソールに次のようにinstall.packages("pyramid")コマンドが実行されてダウンロードされたことがわかる。
> install.packages("pyramid")
URL 'http://cran.rstudio.com/bin/macosx/mavericks/contrib/3.2/pyramid_1.4.tgz' を試しています
Content type 'application/x-gzip' length 24209 bytes (23 KB)
==================================================
downloaded 23 KB
以上で、パッケージ pyramid を利用する準備が整った。
Rパッケージ pyramid を読み込む
Rを起動して、pyramidライブラリを使う準備は簡単、次のように入力するだけだ(記号 > はR世界のプロンプトなので入力する必要はない)。
> library(pyramid)
あるいは、RStudioでは、パッケージ一覧にある pyramid をチェックするだけでもよい。 コンソールには次のようなメッセージが表示される。
> library("pyramid", lib.loc="/Library/Frameworks/R.framework/Versions/3.2/Resources/library")
pyramidライブラリの詳しい使い方を知りたければ、つぎのようにヘルプを呼び出す。
> ?pyramidあるいは、RStudioのパッケージ一覧のパッメージ名をクリックする。
日本の将来推定人口データを取り出す
人口ピラミッドに必要なデータは、年齢階級区分(1年ごとなら年齢のまま、5年ごとなら、0-4歳、5-9歳と集計)と男女年齢別(推定)人口だけです。 公表されているExcelデータをRで読めるように(場合によっては、データを抜き出す/再構成するとかして)、機械可読データ(csv形式)として保存する。
- 元データの入手:日本の将来推計人口(平成24年1月推計)から、[詳細結果表]->[推計結果表]を進んで、将来推計人口2011~2060年の「 表1.出生中位(死亡中位)推計」を選んで、表1−9 男女年齢各歳別人口のExcelデータをPCにダウンロードする)。
- 提供データの検討:ダウンロードしたデータをExcelで開いてみると、アリャ〜〜!。 提供されている表データにおいて、レコード(データの並び)は一列に並んでいない (-.-;) A列に5行目の0歳から59行目の54歳まで、F列に5行目の55歳から55行目の103歳以上まで、と2列に渡ってレコードデータが並んでいる。 人にはスクロールしないでデータが一覧できるので親切なようだが、一括処理したい場合には優しいとは言えない。
- シート:表1-9(4)の平成25年の推定値データを一列に並べかえて、新しい表を作成する。 新しくブック(または新たなシート)を新規作成して、その空白シートにレコードデータが1列に並ぶように貼りつける。 空白シートに貼りつけるデータは、シート:表1-9(4)の範囲 A3:D59 および F3:I55 である。
- まず、表1-9(4)の範囲 A3:D59 をドラッグし選択してからコピー(Ctrl-c)、たとえば空白シートのセル A3 をクリックしてから貼りつけ(Ctr-v)。 次に、表1-9(4)の範囲 F3:I55 をコピーして、上記で貼り付けた最終レコードの次行のセル A60をクリックしてから貼りつけ。 参考のために、表1-9(4)の先頭の2行(範囲 A1:A2)をコピーして、新しいシートのセル A1 をクリックしれ貼りつけておこう。 ただし、新しいシートの4行目は総数で、今の目的には不要なので削除しておく。
- こうして改めて貼り付けた全データは数値として取り扱うために、範囲を選択した上で、[書式]/[セル]から表示形式を数値にする(桁区切り(,)は『使用しない』)。
- csv形式のファイルで保存する。 [ファイル]/[別名で保存]からcsv形式を指定して、たとえば、ファイル名 2013-population.csvで保存。 さらに、保存したcsv形式のファイルをテキストエディタで開いて、年齢を age, 総数を total, 男を male,女を femaleに書き換え、文字コードを Shift-JISから UTF-8に変更しておく(Rでは感じが苦手な場合もある。 Rのデフォルト文字コードはR環境で設定できるが、今後のことを考えるとUTF-8が望ましい)。 これでRで読み込ませるデータファイル 2013-population.csv の準備が完了。
Rで人口ピラミッドを描く
以下では、データファイル 2013-population.csv をRで読み込ませるためのRの作業ディレクトリとして、ファイル2013-population.csvが置かれている場所を設定している。 これがどういうことなのかは、データファイルの読み込みと書き出しを参照。
- まず、ライブラリ pyramid を読み込みこむ。
> library(pyramid)
- テキスト表データファイルの全レコードを関数 read.table( ) を使って読み込む。
人口データファイル 2013-population.csv を読み込むには次のように書く(目的ファイルへのファイルパス指定の記述法についてついては、データファイルの読み込みと書き出しを参照)。
> p <- read.table("2013-population.csv",sep=",",header=TRUE,skip=2)記法 <- は、右辺のデータを左辺の変数に代入するという代入記号。 今の場合、「変数 p に読み込んだファイル情報を格納する」の意味です。 データファイルの先頭からたとえば2行までをコメントとして読み飛ばす(読み込まない)ときには、skip=2 とします。 skipで読み飛ばした実質的に1行目(先頭レコード)がデータ値でなく、フィールド名の並びとなっている行をヘッダー(header)という。 先頭レコードがヘッダーであるがどうかを header=TRUE で指定。 sep="," は、csvファイルのレコードデータにおける区切り記号がカンマ (,) であるという意味。 - ちゃんとデータが読み込まれているかを確認する。
次のように変数名 p を入力するだけだ。
このとき、ヘッダを除いたレコード(データ並び)には、左端に1から始まる行番号が付与され、読み込んだレコード内容が1行ずつ表示される。
元のデータファイルの3行目にあった(skip=2で読み飛ばしたために、実質的に読み込んだ)先頭レコードはラベル名の並び age, total, male, femaleとなっていることに注意しよう。
read.table で header=TRUE としたためだ。
> p age total male femal 1 0 1004 515 489 2 1 1018 522 496 3 2 1051 540 512 4 3 1039 532 507 5 4 1042 533 509 6 5 1072 548 523 7 6 1067 546 521 8 7 1059 542 517 9 8 1056 540 515 ... ... 104 103 6 1 5 105 104 3 0 3 106 105+ 4 0 3 - 表データの指定した列のデータだけを表示させる。
たとえば、age列(1列目)に並んでいるデータ 0,1,2,3,4,5,...を表示させるには、age列が行列データの1列目であることに注意して p[,1] で指定する。
> p[,1] [1] 0 1 2 3 4 5 6 7 8 9 10 11 [13] 12 13 14 15 16 17 18 19 20 21 22 23 [25] 24 25 26 27 28 29 30 31 32 33 34 35 [37] 36 37 38 39 40 41 42 43 44 45 46 47 [49] 48 49 50 51 52 53 54 55 56 57 58 59 [61] 60 61 62 63 64 65 66 67 68 69 70 71 [73] 72 73 74 75 76 77 78 79 80 81 82 83 [85] 84 85 86 87 88 89 90 91 92 93 94 95 [97] 96 97 98 99 100 101 102 103 104 105+ 106 Levels: 0 1 10 100 101 102 103 104 105+ 11 12 13 14 15 ... 99
左端の[1],[13],[25],..は、リストデータの表示された左端が[1]個目(データは 0)、[13]個目(データは 12)、[25]個目(データは 24)であることを示している(ウィンドウ幅などによって異なる)。 female列(4列目)のデータシストを表示するには、4列目であることから p[,4] と表すことになる。 - pyramidライブラリの使い方によれば、上のようなデータセットについては、次のように入力すると(コピペしてください)、人口ピラミッド図が得られる(詳しくはパッケージ pyramidのhelp参照)。
Leftにはmale列のデータを、Rightにはfemale列のデータを、Centerにはage列のデータをセットしなければなりません。
したがって、読み込んだデータセット p の場合にはそれぞれ p[,3], p[,4], p[,1] とするわけだ。
p <- read.table("2013-population.csv",sep=",",header=TRUE,skip=2) pyramids(Left=p[,3], Right=p[,4], Center=p[,1], Laxis=seq(0,1200,len=7), Clab="Age", Llab="Male", Rlab="Female", Cstep=10, main="Population Pyramid of Japan 2013(unit: 10^3 )\n ")