現在 Python が人気のあるプログラミング言語である理由として データ分析や機械学習を簡単に行うことができることを挙げましたが、 今日とりあげる pandas はよく使われるデータ分析用ライブラリの一つです。 多様な形式のデータに対して、簡単に集計、可視化、数値計算のための処理などを行うことができます。
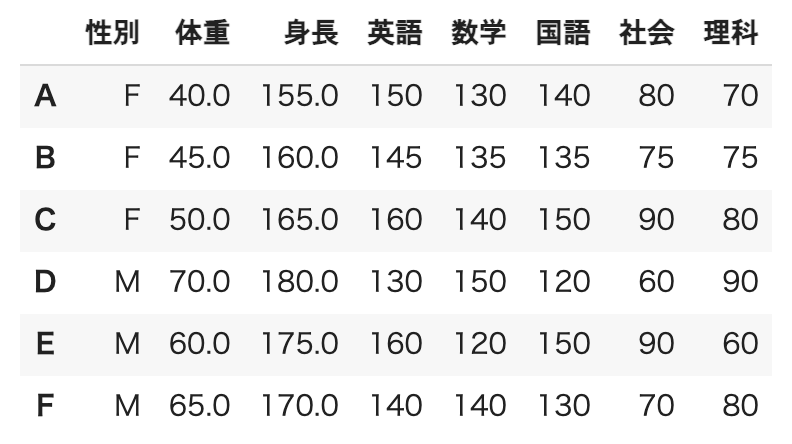
ここでは、以下のデータを用いて pandas の簡単な使い方について試していくことにしましょう。
このデータでは、6人の学生、性別、体重、身長、および英数国理社のテストの点数がデータとして与えられています。
(データの中には文字列と数値が混在していますが、Python のリストではこれらのデータを問題なく扱うことができます。)
これを pandas で取り扱うために、DataFrane オブジェクトを作成してみましょう。
以下のプログラムを実行すると、上で示したデータが表示されます。
# pandas を別名 pd として import
import pandas as pd
# DataFarme オブジェクトの作成
df = pd.DataFrame({
"性別":["F","F","F","M","M","M"],
"体重":[40.0,45.0,50.0,70.0,60.0,65.0],
"身長":[155.0,160.0,165.0,180.0,175.0,170.0],
"英語":[150,145,160,130,160,140],
"数学":[130,135,140,150,120,140],
"国語":[140,135,150,120,150,130],
"社会":[80,75,90,60,90,70],
"理科":[70,75,80,90,60,80]
} ,
index=["A","B","C","D","E","F"]
)
# DataFrame の中身確認
df
性別、体重といったそれぞれの項目名は index として保持されており、上のプログラムに続けて
df.columns
と入力すると、各項目名が表示されます。 また、身長と体重だけ表示させたい場合には、以下のように入力します。
df[["体重","身長"]]
最初の2名や最後の2名のデータを表示したい場合には、
df.head(2)
df.tail(2)
とすればOKです。
また、以下のようにすることで下から2行分を除いて表示させることも可能です。
df.head(-2)
もちろん、tail でも同様のことが可能です(下の例は、上から3行分を除いている)
df.tail(-3)
さらに、これらを組み合わせて以下のように入力すれば、最初の4名の身長、体重データのみを表示できます。
df[["体重","身長"]].head(4)
これだけだとリスト等を使っても同じようなことは比較的簡単にできますが、
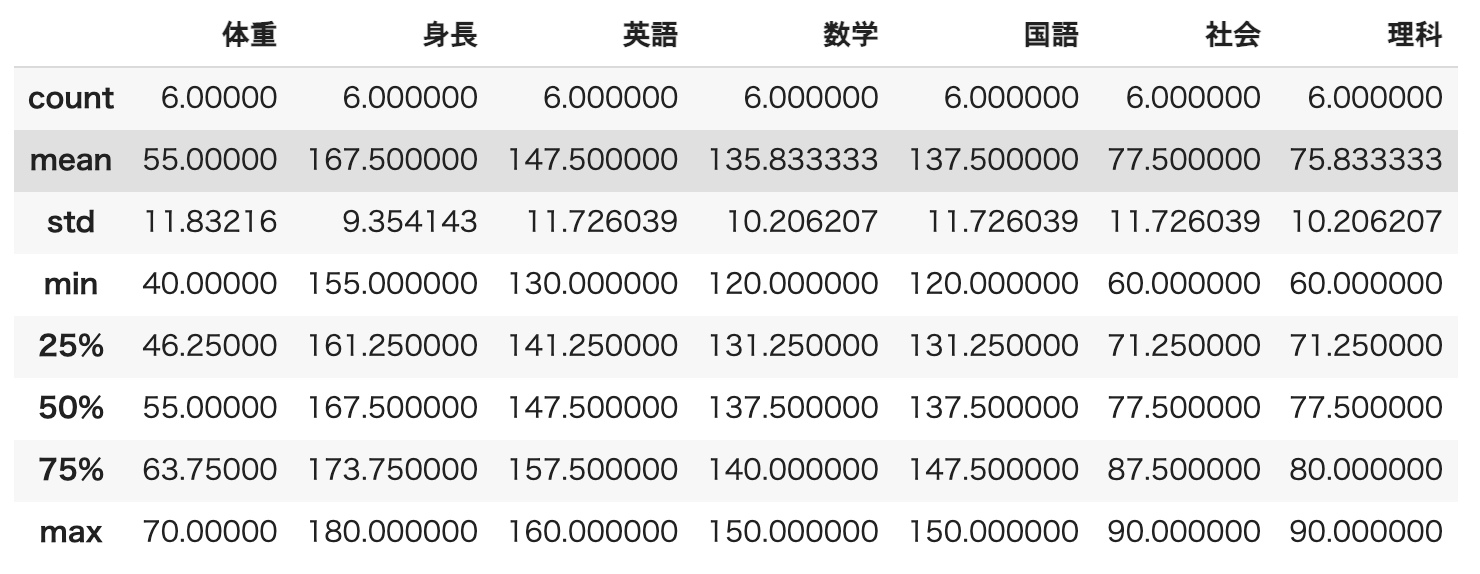
その他にも基本的な統計量の計算も簡単にできます。
(要素数、平均値、標準偏差、最小値、第一四分位点、中央値、第三四分位点、最大値)
もちろん、統計量が計算できない数値以外のデータは除外されます。
df.describe()
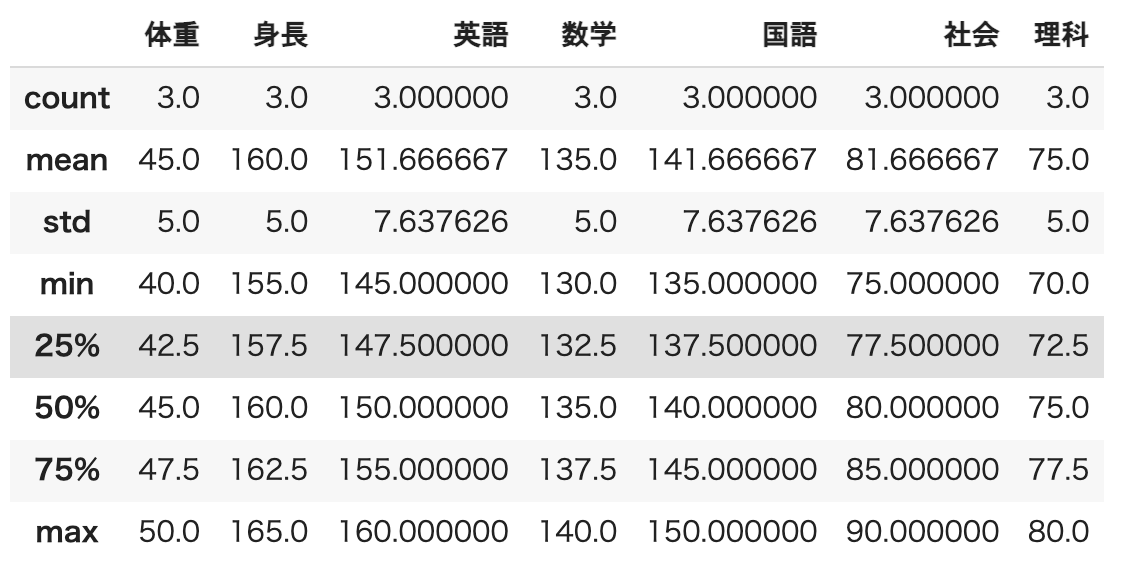
論理演算子を利用して、特定のデータのみについての統計量を計算することもできます。 以下では、女性のグループ(性別 "F")についての統計量を計算しています。
df[df["性別"]=="F"].describe()
これを応用して、男女の成績比較(各教科の平均点の比較)を行いたい場合には以下のようにします。
print( "女性(female)の平均点" )
print( df[df["性別"]=="F"][["英語","数学","国語","社会","理科"]].mean() )
print("")
print( "男性(male)の平均点" )
print( df[df["性別"]=="M"][["英語","数学","国語","社会","理科"]].mean() )
条件を複数設定することも可能です。例えば、英語と国語がともに平均点を超えている学生のみを表示する場合には以下のようにします。
print("英語の平均点:", df["英語"].mean())
print("国語の平均点:", df["国語"].mean())
df[(df["英語"]>=df["英語"].mean()) & (df["国語"]>=df["国語"].mean())]
以下のようにすることで、データのソートも簡単に実行できます。
df.sort_values( by = "英語" , ascending = False )

ascending が False の場合には大きい順、True の場合には小さい順に並びます。
次に、データの可視化を行なってみましょう。 可視化に関しては、内部的には matplotlib を利用しているので、第8回とほぼ同様にできます。
可視化するにあたって、import や日本語を扱うにあたっての「おまじない」が必要になるので、 まずは以下を実行してください。
!pip install japanize-matplotlib import matplotlib import japanize_matplotlib import matplotlib.pyplot as plt japanize_matplotlib.japanize()
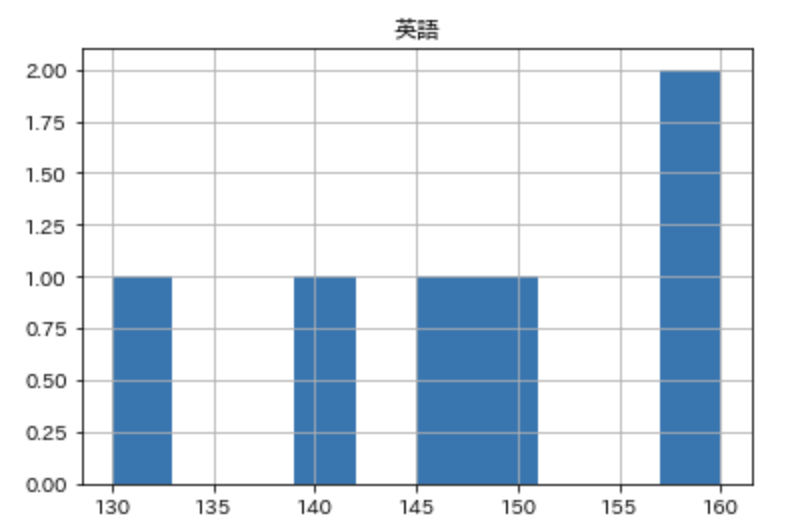
これで準備は完了なので、まずはヒストグラムを表示させてみましょう。
df.hist( ["英語"] )
plt.show()
複数のグラフでも、簡単に表示させることができます。
df.hist( ["英語","数学","国語"] )
plt.show()
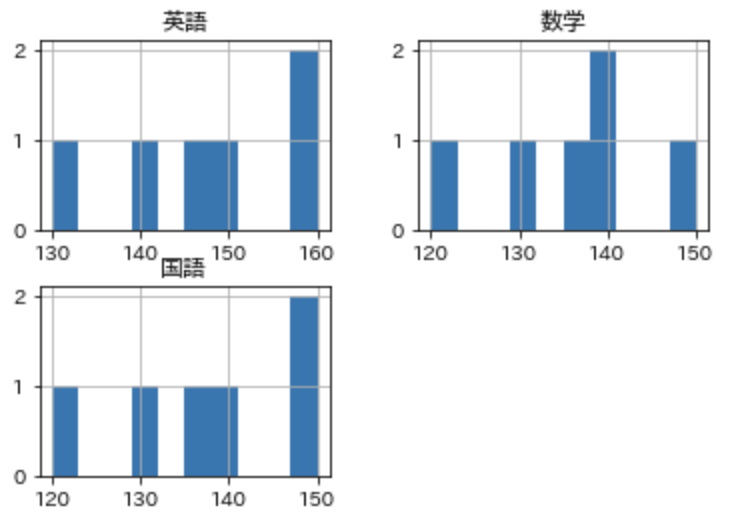
df.hist()
plt.show()
とすれば、すべてのデータについて表示させることも可能です。
( df.hist(figsize=(9,9)) などとした方が、見やすく表示される )
例は挙げませんが、論理演算子を利用して特定のデータだけ表示させることももちろん可能です。
次に散布図を描いた上で、相関係数を計算してみましょう。
まずは以下のように、英語と数学、英語と国語についての散布図を描いてみます。
df.plot( x = "英語" , y = "数学" , kind="scatter" , s = 500 )
df.plot( x = "英語" , y = "国語" , kind="scatter" , s = 500 )
plt.show()
ちなみに、一番最後の引数 s=500 は散布図でプロットする点のサイズを指定しています。
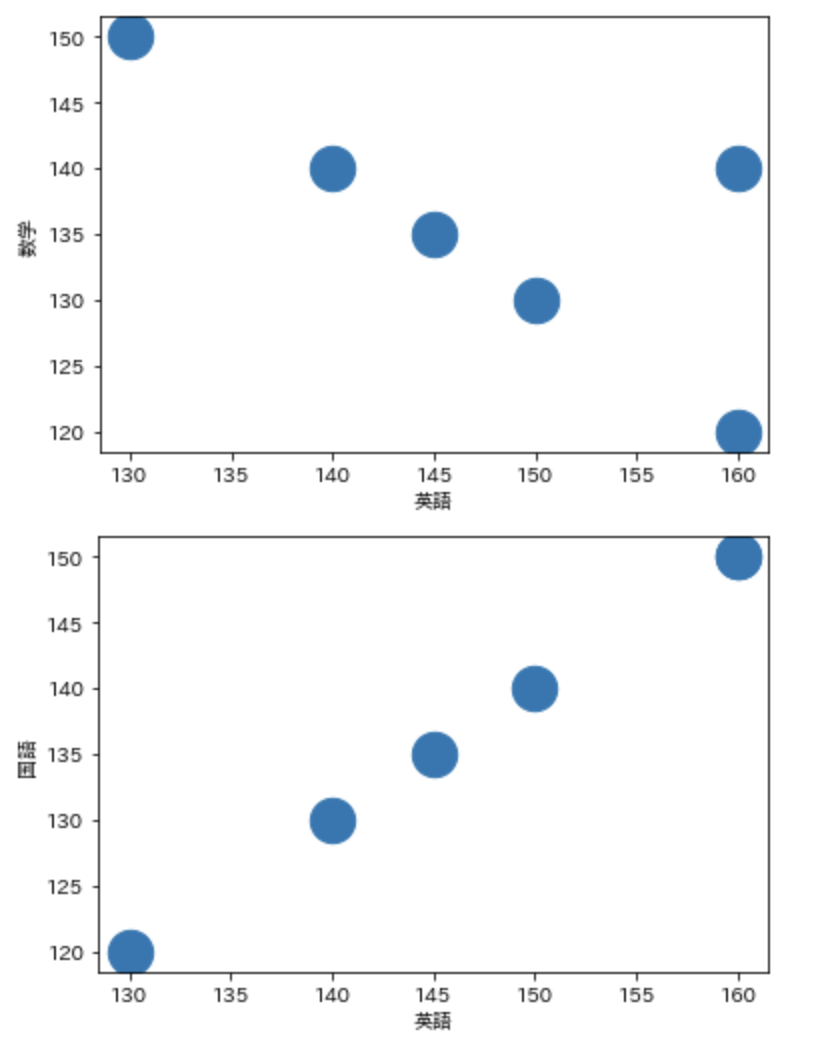
これを見ると、英語と数学は負の相関があるのに対し、英語と国語は正の相関があるのが分かります。
これを定量的に確認してみましょう。
各項目についての相関係数は、下の1行のみで簡単に計算できます。
df.corr(numeric_only=True)

これを見ると、先に述べた相関関係がきちんと確認できます。
さらにseaborn というライブラリを利用すると、相関係数をよりわかりやすく可視化(ヒートマップで表示)することもできます。
import seaborn as sns sns.heatmap(df.corr(numeric_only=True)) plt.show()
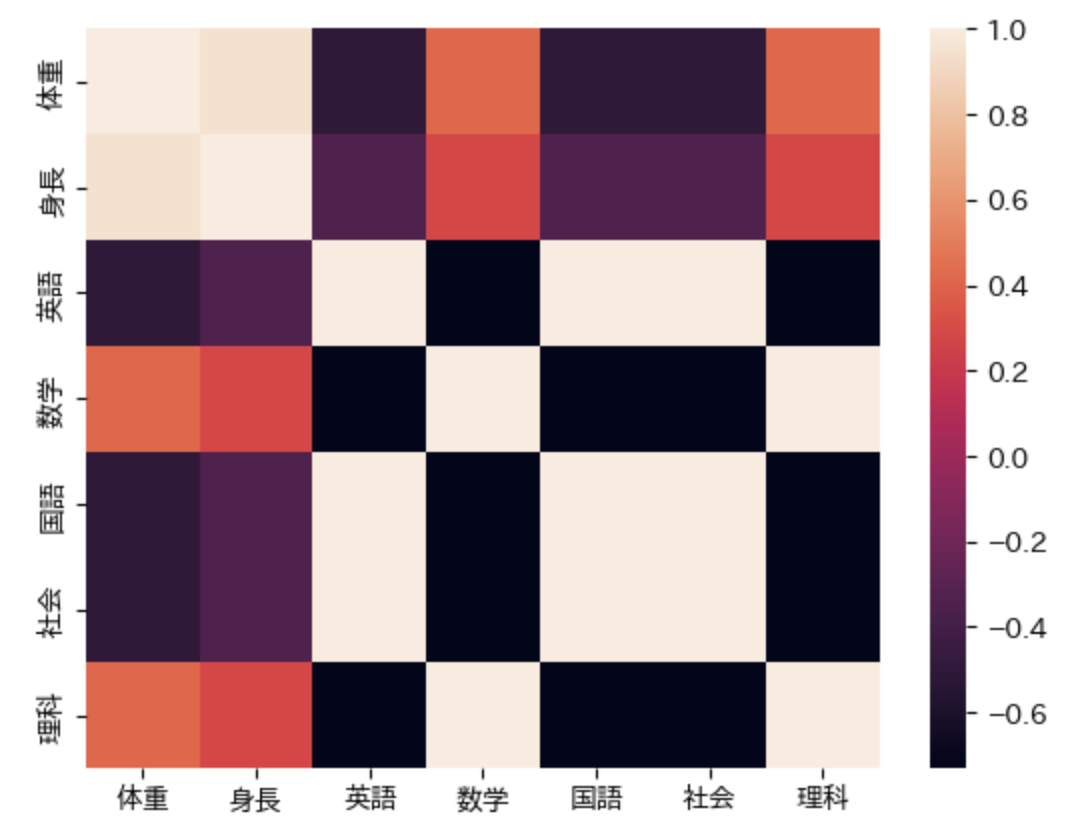
ここでは、pandas を使って実際のデータの簡単な分析を行なってみましょう。
ここでは、カリフォルニアの住宅価格に関するデータセットを利用します。(ただし、今回は価格のデータは使いません)
まず以下を実行して、データセットを取得します。
from sklearn.datasets import fetch_california_housing housing = fetch_california_housing() housing_df = pd.DataFrame(housing.data, columns=housing.feature_names)
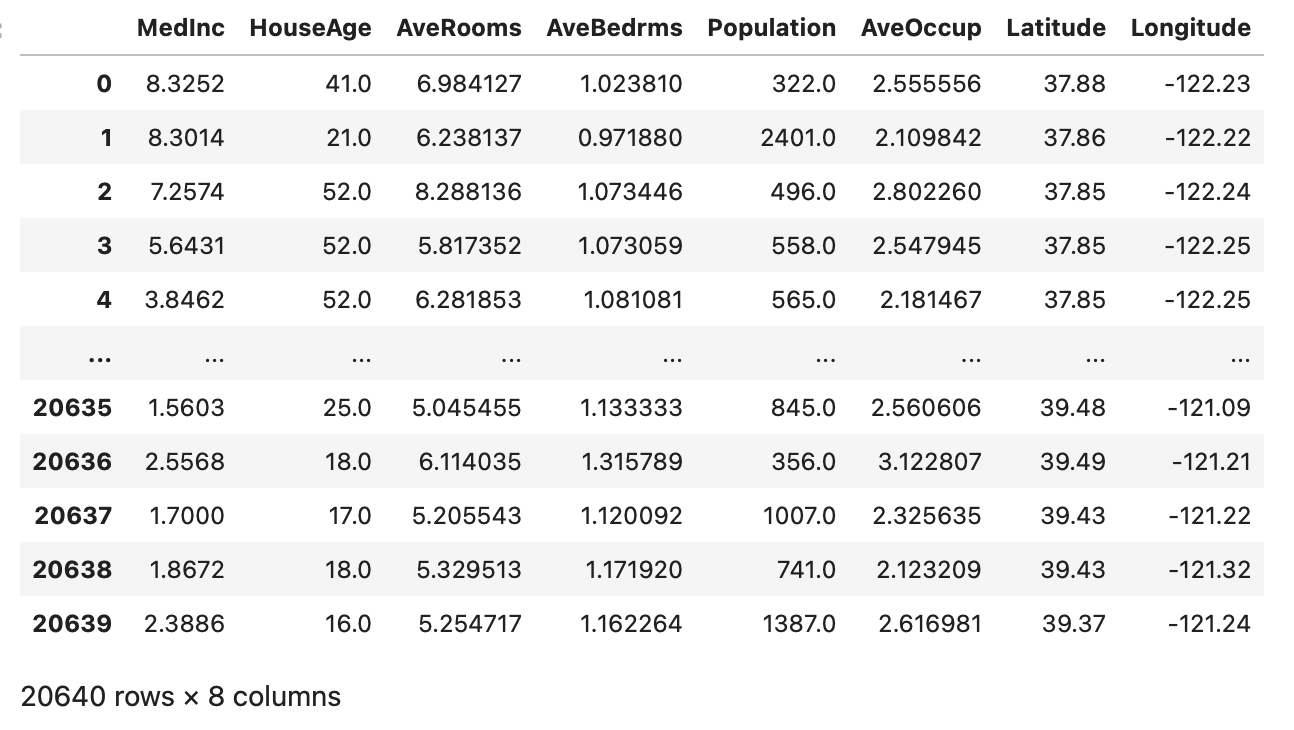
次に、
housing_df
として、中身のデータを確認してみましょう。
データの各項目については、こちらで詳しく説明されています。
(日本語ならここが分かりやすいかも)
先ほどと同様に、グラフを描くこともできます。
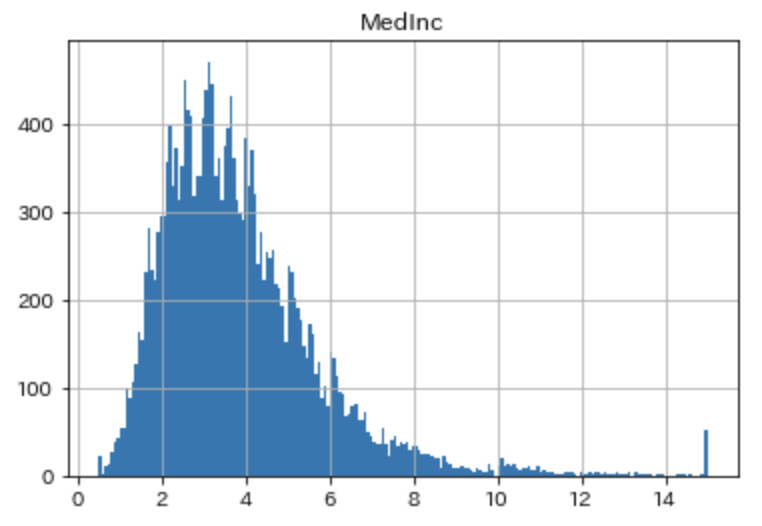
housing_df.hist(["MedInc"],bins=200)
plt.show()
カリフォルニアの住宅価格に関するデータセットの他にも、ワインの種類や糖尿病患者のデータなど
様々なデータセットが簡単に扱うことができます。
例えば、糖尿病のデータセットなら以下のようにすれば、簡単に利用できます。
from sklearn.datasets import load_diabetes diabetes = load_diabetes(scaled=False) diabetes_df = pd.DataFrame(diabetes.data, columns=diabetes.feature_names)
データの各項目については、こちらに詳しく説明されています。
「課題1」と「課題2」の両方について作成したプログラムを提出してください。 課題1と課題2は一つのファイルに入れてしまって構いません。
ただし、コメント文として
学生番号、名前、プログラムの簡単な説明
を書く事。
ファイル名は、12-rep.ipynb として、 提出したファイル単体で実行できるようにすること。
提出締め切り: 2024年12月23日19時